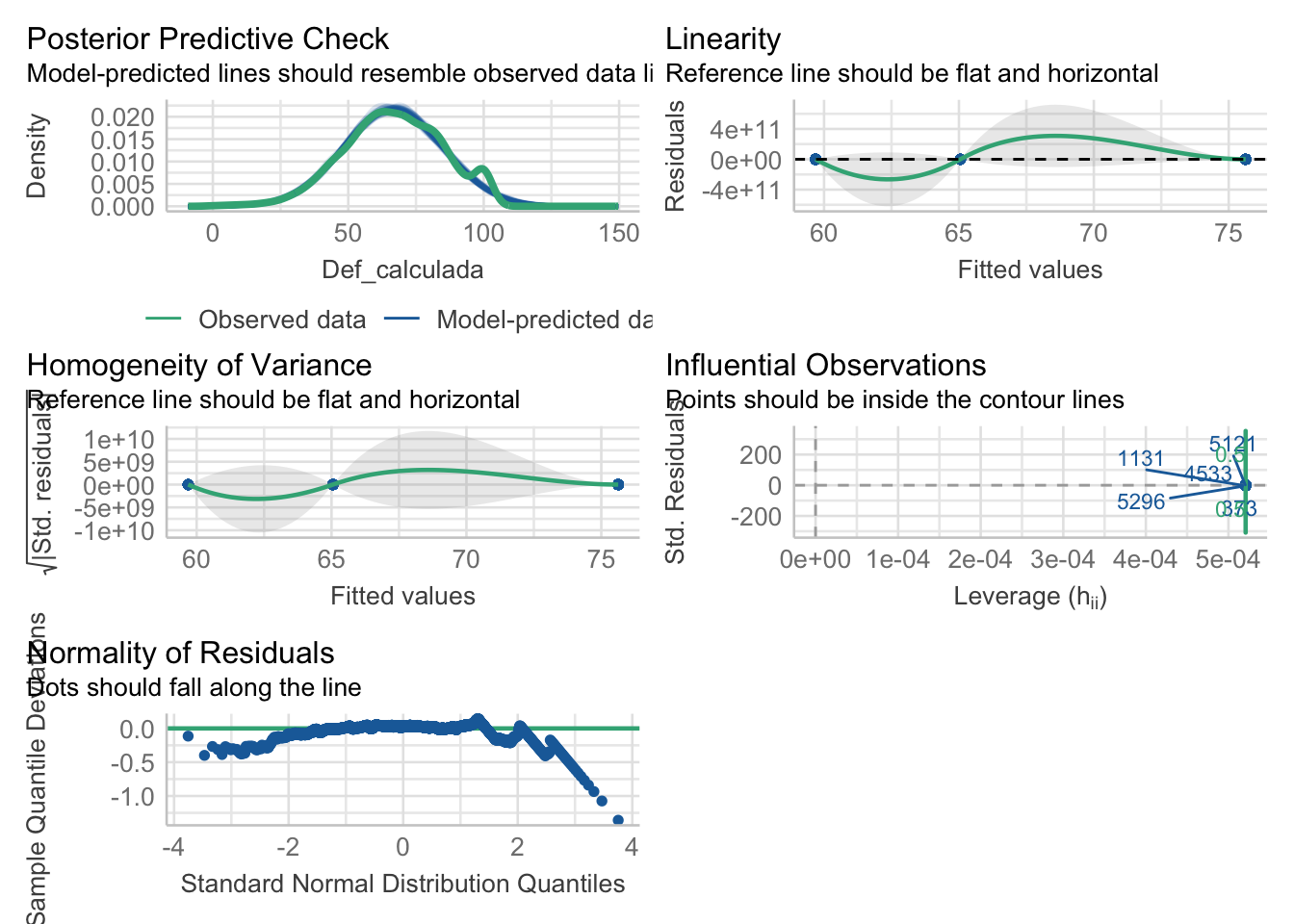
Warning: Non-normality of residuals detected (p < .001).
check
Codigo
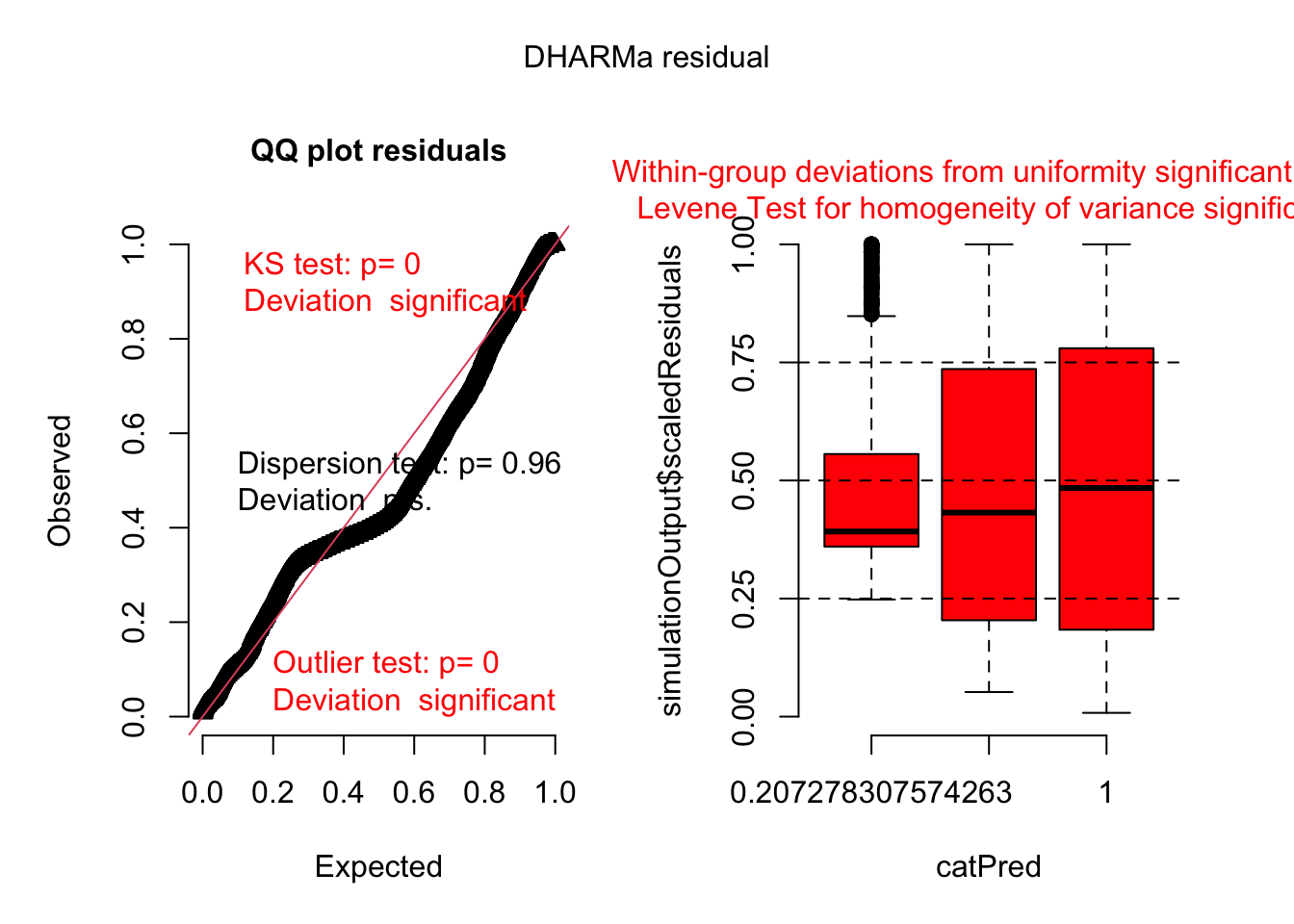
plot(simulateResiduals(aov_inc))
Codigo
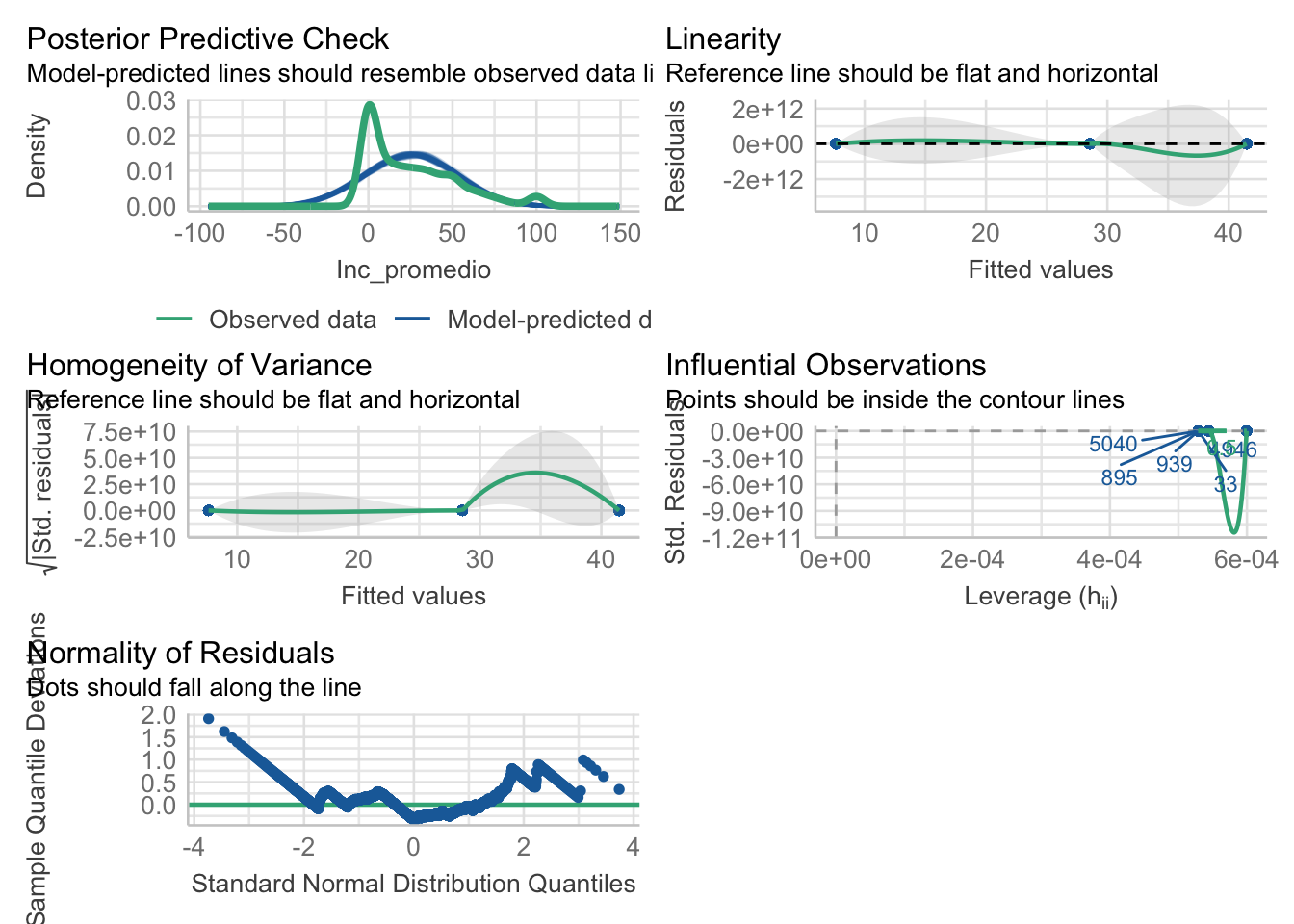
check_model(aov_inc)
No cumplen con los supuestos de normalidad y homocedasticidad, hay varias alternativas que puedes considerar para realizar análisis estadísticos apropiados.
Transformaciones de Datos
Pruebas No Paramétricas El análisis no paramétrico no asume una distribución específica para los datos y es más flexible en términos de los supuestos que hace.
Modelos Generalizados
Resampling Methods
Análisis Robustos
Análisis de Varianza no Paramétrico
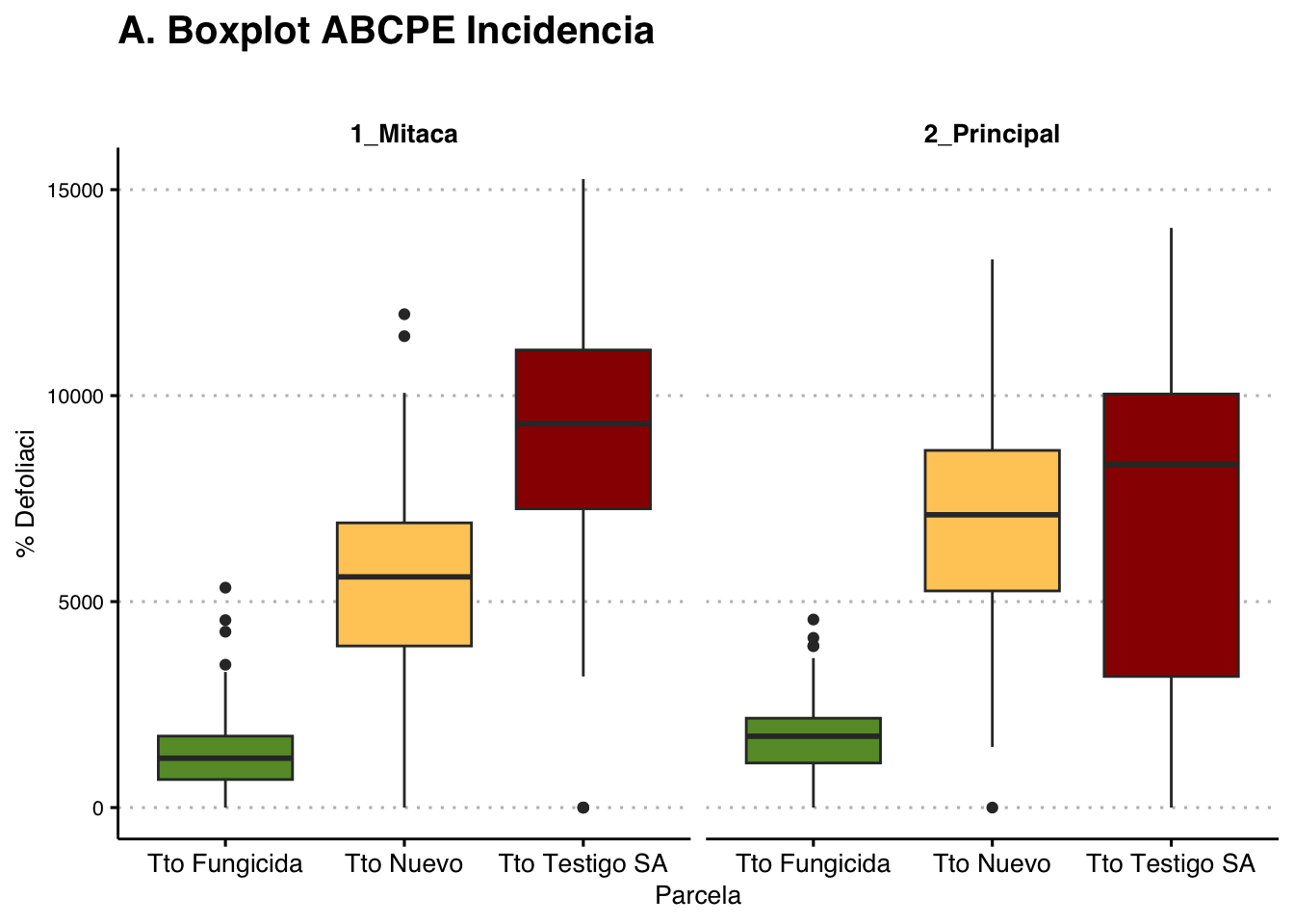
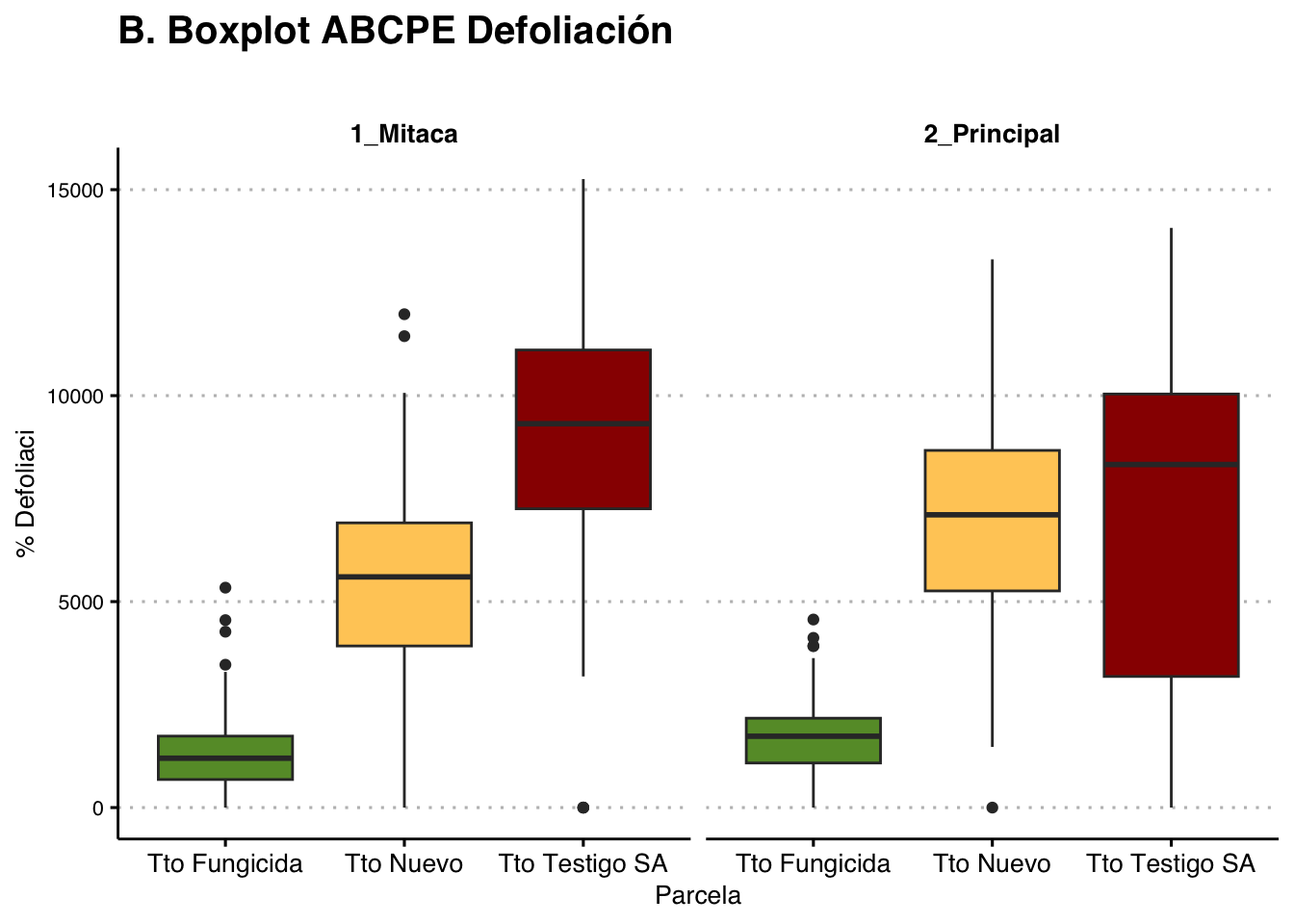
Área Bajo la Curva del Progreso de la Enfermedad (AUDPC)
# Test de Kruskal-Walliskruskal.test(audpc ~ Parcela, data = dat1_audpc_f)
Kruskal-Wallis rank sum test
data: audpc by Parcela
Kruskal-Wallis chi-squared = 220.4, df = 2, p-value < 2.2e-16
Interpretación del Test de Kruskal-Wallis: Este test no requiere la asunción de normalidad. Si el p-valor es menor que 0.05, hay diferencias significativas entre los grupos.
Study: dat1_audpc_f$audpc ~ dat1_audpc_f$Parcela
Kruskal-Wallis test's
Ties or no Ties
Critical Value: 220.4003
Degrees of freedom: 2
Pvalue Chisq : 0
dat1_audpc_f$Parcela, means of the ranks
dat1_audpc_f.audpc r
Tto Fungicida 109.8937 160
Tto Nuevo 284.4688 160
Tto Testigo SA 327.1375 160
Post Hoc Analysis
t-Student: 1.96495
Alpha : 0.05
Minimum Significant Difference: 22.43448
Treatments with the same letter are not significantly different.
dat1_audpc_f$audpc groups
Tto Testigo SA 327.1375 a
Tto Nuevo 284.4688 b
Tto Fungicida 109.8937 c
Codigo
aov_inc2 <-aov(audpc~ Parcela, data = dat1_audpc_f)aov_inc2
Call:
aov(formula = audpc ~ Parcela, data = dat1_audpc_f)
Terms:
Parcela Residuals
Sum of Squares 3490469797 3788596830
Deg. of Freedom 2 477
Residual standard error: 2818.253
Estimated effects may be unbalanced
# Crear el modelo ANOVAaov_def <-aov(Def_calculada~ Parcela, data = CLR_)# Resumen del modelosummary(aov_def)
Df Sum Sq Mean Sq F value Pr(>F)
Parcela 2 252680 126340 445.5 <2e-16 ***
Residuals 5757 1632470 284
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
homocedasticidad
Codigo
check_heteroscedasticity(aov_def)
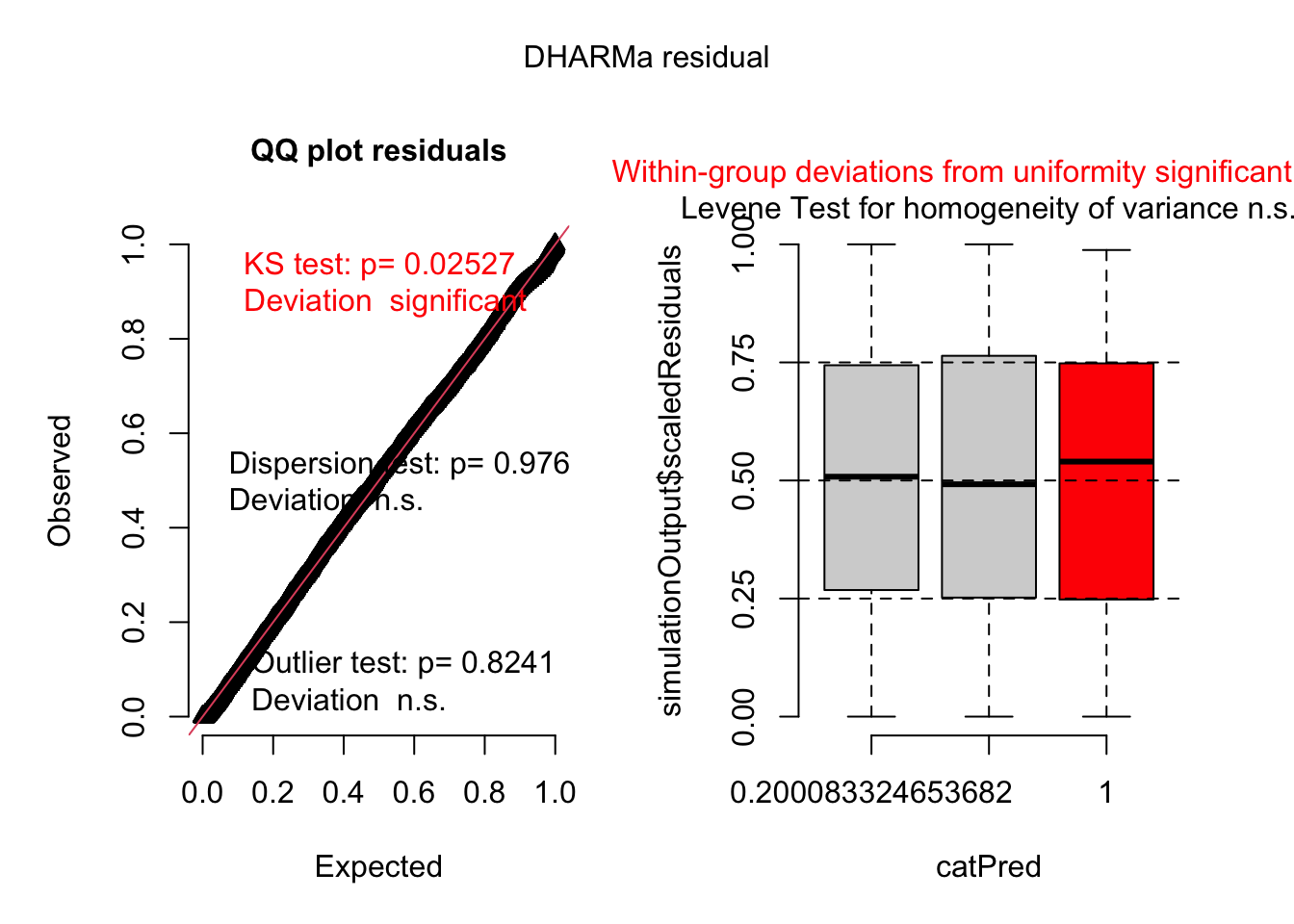
OK: Error variance appears to be homoscedastic (p = 0.316).
Normalidad
Codigo
check_normality(aov_def)
Warning: Non-normality of residuals detected (p = 0.006).
check
Codigo
plot(simulateResiduals(aov_def))
Codigo
check_model(aov_def)
Se cumplen con el supuestos de normalidad, pero no con la homocedasticidad, hay varias alternativas que puedes considerar para realizar análisis estadísticos apropiados.
Transformaciones de Datos
Pruebas No Paramétricas
Modelos Generalizados
Resampling Methods
Análisis Robustos
Análisis de Varianza no Paramétrico
Transformaciones de Datos
Pruebas No Paramétricas El análisis no paramétrico no asume una distribución específica para los datos y es más flexible en términos de los supuestos que hace.
Modelos Generalizados
Resampling Methods
Análisis Robustos
Análisis de Varianza no Paramétrico
Área Bajo la Curva del Progreso de la Enfermedad (AUDPC)
# Test de Kruskal-Walliskruskal.test(audpc ~ Parcela, data = dat1_audpc_f)
Kruskal-Wallis rank sum test
data: audpc by Parcela
Kruskal-Wallis chi-squared = 220.4, df = 2, p-value < 2.2e-16
Interpretación del Test de Kruskal-Wallis: Este test no requiere la asunción de normalidad. Si el p-valor es menor que 0.05, hay diferencias significativas entre los grupos.
Study: dat1_audpc_f$audpc ~ dat1_audpc_f$Parcela
Kruskal-Wallis test's
Ties or no Ties
Critical Value: 220.4003
Degrees of freedom: 2
Pvalue Chisq : 0
dat1_audpc_f$Parcela, means of the ranks
dat1_audpc_f.audpc r
Tto Fungicida 109.8937 160
Tto Nuevo 284.4688 160
Tto Testigo SA 327.1375 160
Post Hoc Analysis
t-Student: 1.96495
Alpha : 0.05
Minimum Significant Difference: 22.43448
Treatments with the same letter are not significantly different.
dat1_audpc_f$audpc groups
Tto Testigo SA 327.1375 a
Tto Nuevo 284.4688 b
Tto Fungicida 109.8937 c
Codigo
aov_inc2 <-aov(audpc~ Parcela, data = dat1_audpc_f)aov_inc2
Call:
aov(formula = audpc ~ Parcela, data = dat1_audpc_f)
Terms:
Parcela Residuals
Sum of Squares 3490469797 3788596830
Deg. of Freedom 2 477
Residual standard error: 2818.253
Estimated effects may be unbalanced