Codigo
# Cargar paquetes necesarios
library(tidyverse)
library(ggplot2)
library(gsheet)
library(dplyr)
library(drc)
library(ec50estimator)
library(ggthemes)
library(DT)El análisis de regresión no lineal es esencial cuando los datos no siguen un patrón lineal y es necesario utilizar técnicas que capturen la relación entre las variables de manera más precisa. Este tipo de análisis es crucial en estudios donde las relaciones entre variables no pueden ser adecuadamente modeladas mediante funciones lineales.
A continuación, se presenta una guía práctica para realizar un análisis de regresión no lineal en RStudio utilizando diversos paquetes y funciones.
En muchos estudios, las relaciones entre las variables pueden ser complejas y no seguir un patrón lineal simple. La regresión no lineal permite capturar estas relaciones complejas y proporciona una mejor comprensión de los datos. Es especialmente útil en casos donde la respuesta varía de manera no constante con la dosis o tratamiento, como en estudios de toxicidad, farmacología, biología, y muchas otras áreas científicas y de ingeniería.
Primero, instalamos y cargamos los paquetes necesarios para el análisis.
# Cargar paquetes necesarios
library(tidyverse)
library(ggplot2)
library(gsheet)
library(dplyr)
library(drc)
library(ec50estimator)
library(ggthemes)
library(DT)Importamos los datos desde una hoja de cálculo de Google Sheets que contiene datos sobre la sensibilidad a fungicidas.
# Importar datos desde Google Sheets
dat <- gsheet2tbl("https://docs.google.com/spreadsheets/d/15pCj0zljvd-TGECe67OMt6sa21xO8BqUgv4d-kU8qi8/edit#gid=0")
dat |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))Preparamos los datos para el análisis, agrupándolos y calculando la media de GC.
# Evitar notación científica
options(scipen=999)
# Procesar datos
dat2 <- dat |>
dplyr::select(-Isolate, -Population) |>
group_by(Code, Year, Dose) |>
summarise(GC_mean = mean(GC))
dat2 |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))Creamos un gráfico para visualizar los datos de uno de los códigos específicos (por ejemplo, “FGT152”) utilizando ggplot2.
# Filtrar datos para un código específico
FGT152 <- dat2 |> filter(Code == "FGT152")
# Crear gráfico
FGT152 |>
ggplot(aes(factor(Dose), GC_mean)) +
geom_point() +
geom_line() +
facet_wrap(~ Code) +
theme_few()+
labs(title = "Curva Dosis-Respuesta para FGT152", x = "Dosis", y = "GC Media")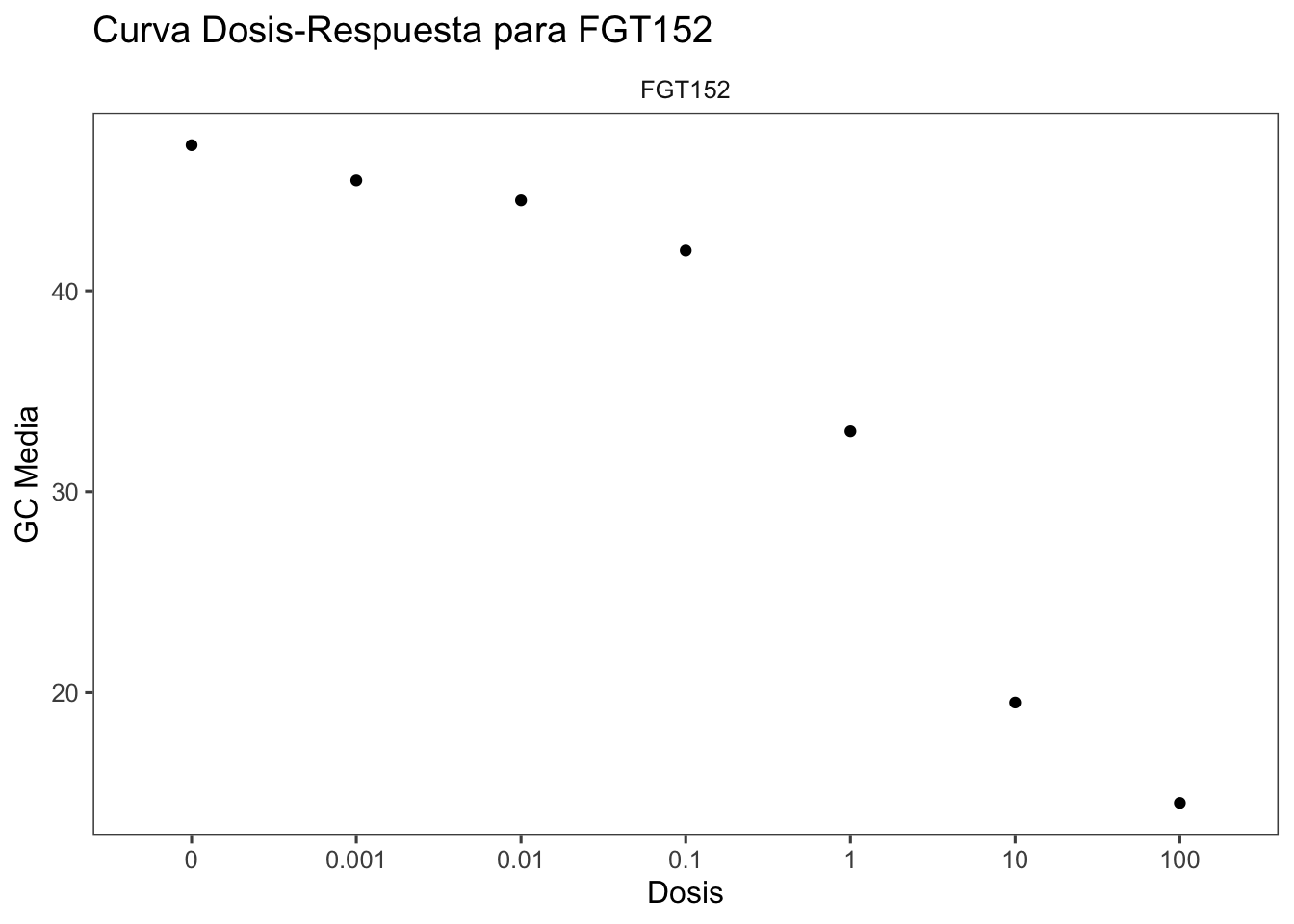
Utilizamos el paquete drc para ajustar un modelo de regresión no lineal y calcular el EC50.
Este modelo se ajusta utilizando los siguientes comandos:
# Ajustar modelo log-logístico de tres parámetros
drc1 <- drm(GC_mean ~ Dose, data = FGT152, fct = LL.3())
AIC(drc1)[1] 33.60846summary(drc1)
Model fitted: Log-logistic (ED50 as parameter) with lower limit at 0 (3 parms)
Parameter estimates:
Estimate Std. Error t-value p-value
b:(Intercept) 0.401905 0.053427 7.5225 0.001672 **
d:(Intercept) 47.540342 1.459890 32.5643 5.302e-06 ***
e:(Intercept) 7.220130 2.340120 3.0854 0.036739 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error:
1.993805 (4 degrees of freedom)plot(drc1)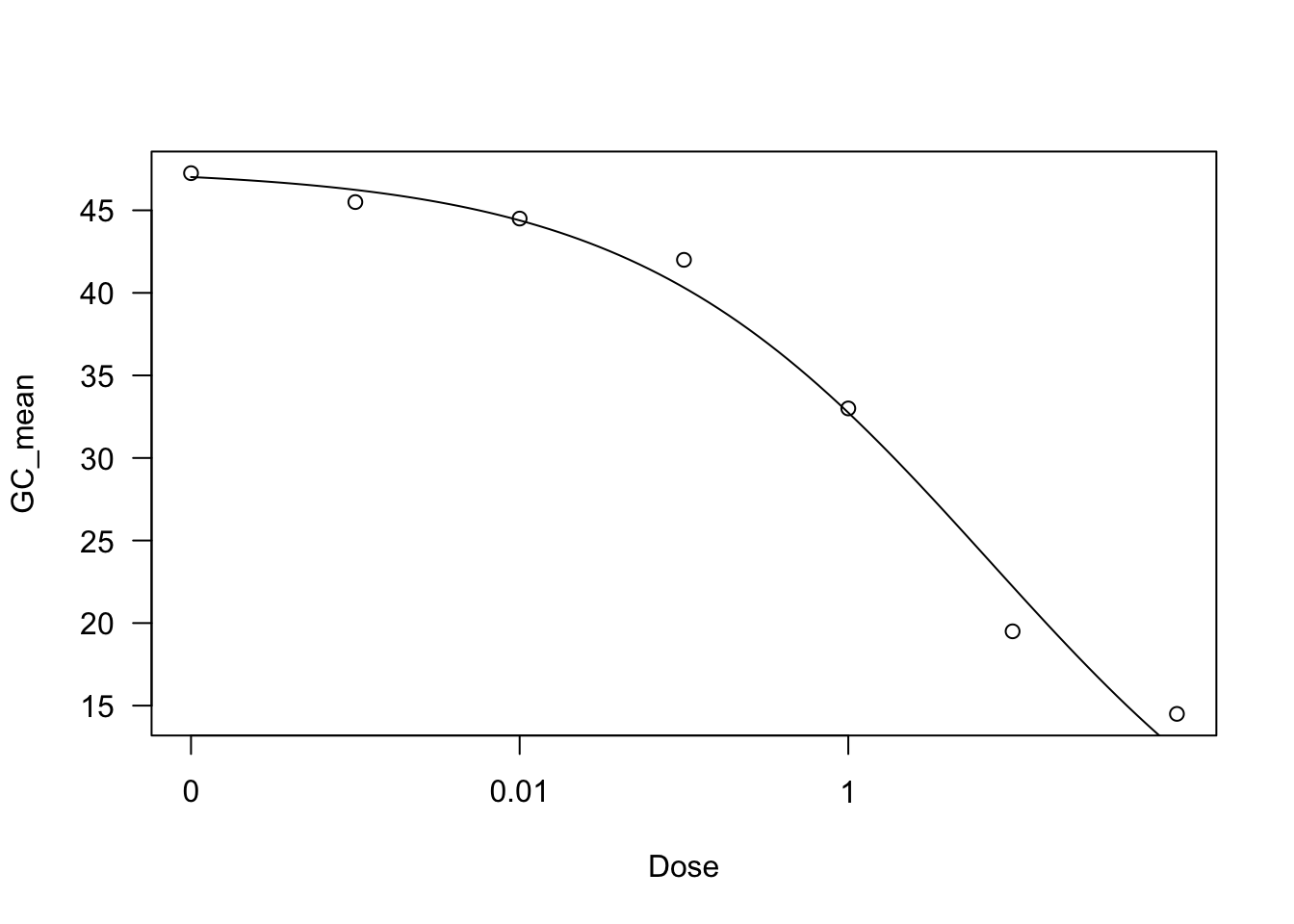
ED(drc1, 50)
Estimated effective doses
Estimate Std. Error
e:1:50 7.2201 2.3401Este modelo puede proporcionar un mejor ajuste basado en el AIC:
# Ajustar modelo Weibull de tres parámetros
drc1 <- drm(GC_mean ~ Dose, data = FGT152, fct = W1.3())
AIC(drc1)[1] 37.75192summary(drc1)
Model fitted: Weibull (type 1) with lower limit at 0 (3 parms)
Parameter estimates:
Estimate Std. Error t-value p-value
b:(Intercept) 0.28354 0.04760 5.9567 0.003987 **
d:(Intercept) 48.38112 2.09996 23.0390 0.00002103 ***
e:(Intercept) 30.12379 12.58003 2.3946 0.074796 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error:
2.680509 (4 degrees of freedom)plot(drc1)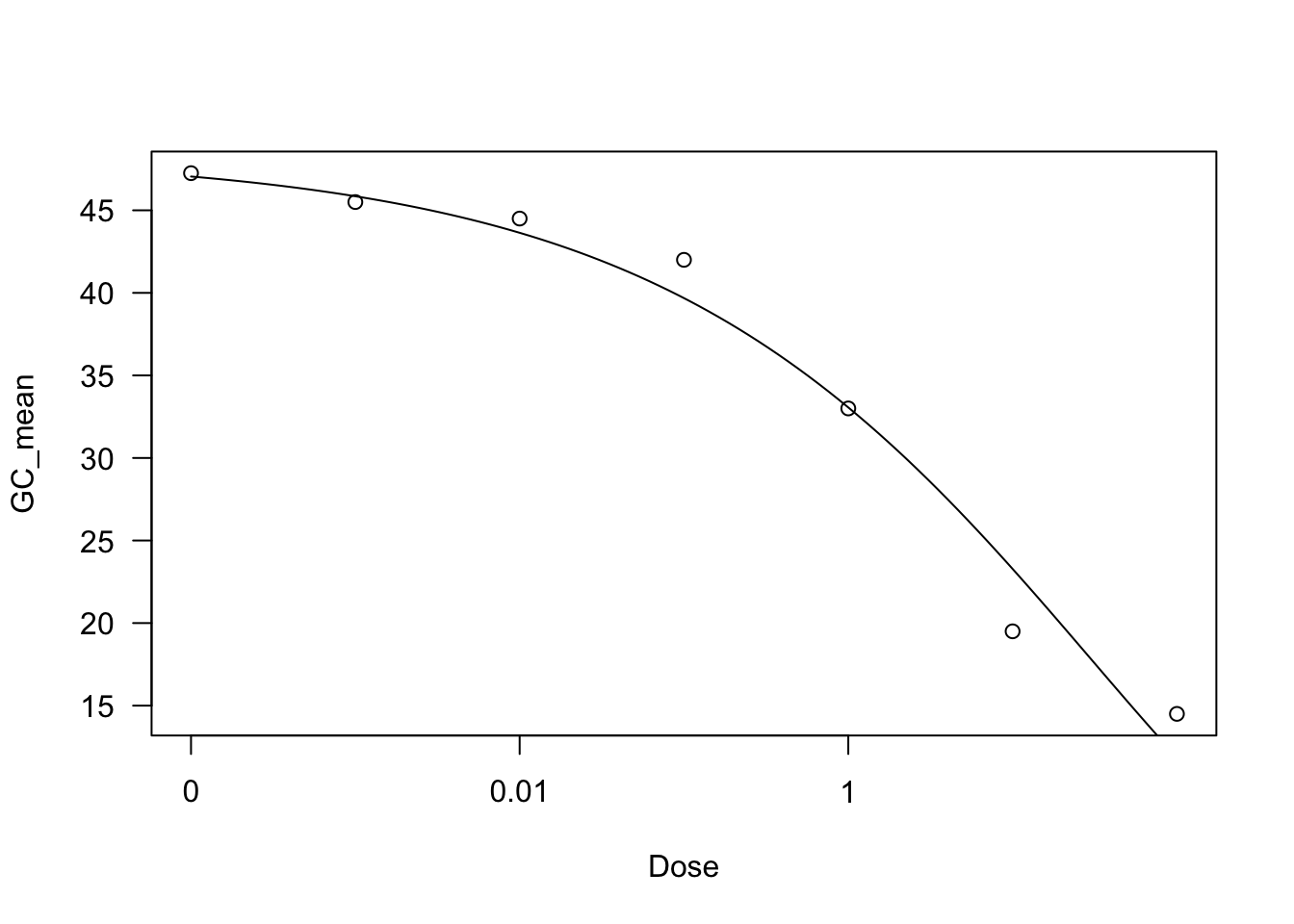
ED(drc1, 50)
Estimated effective doses
Estimate Std. Error
e:1:50 8.2704 3.6719Visualizamos los resultados del modelo ajustado utilizando ggplot2.
# Obtener predicciones del modelo
predictions <- data.frame(Dose = seq(min(FGT152$Dose), max(FGT152$Dose), length.out = 100))
predictions$GC_mean <- predict(drc1, newdata = predictions)
# Crear gráfico con predicciones
FGT152 |>
ggplot(aes(Dose, GC_mean)) +
geom_point() +
geom_line(data = predictions, aes(Dose, GC_mean), color = "blue") +
labs(title = "Modelo Weibull de Tres Parámetros", x = "Dosis", y = "GC Media") +
theme_few()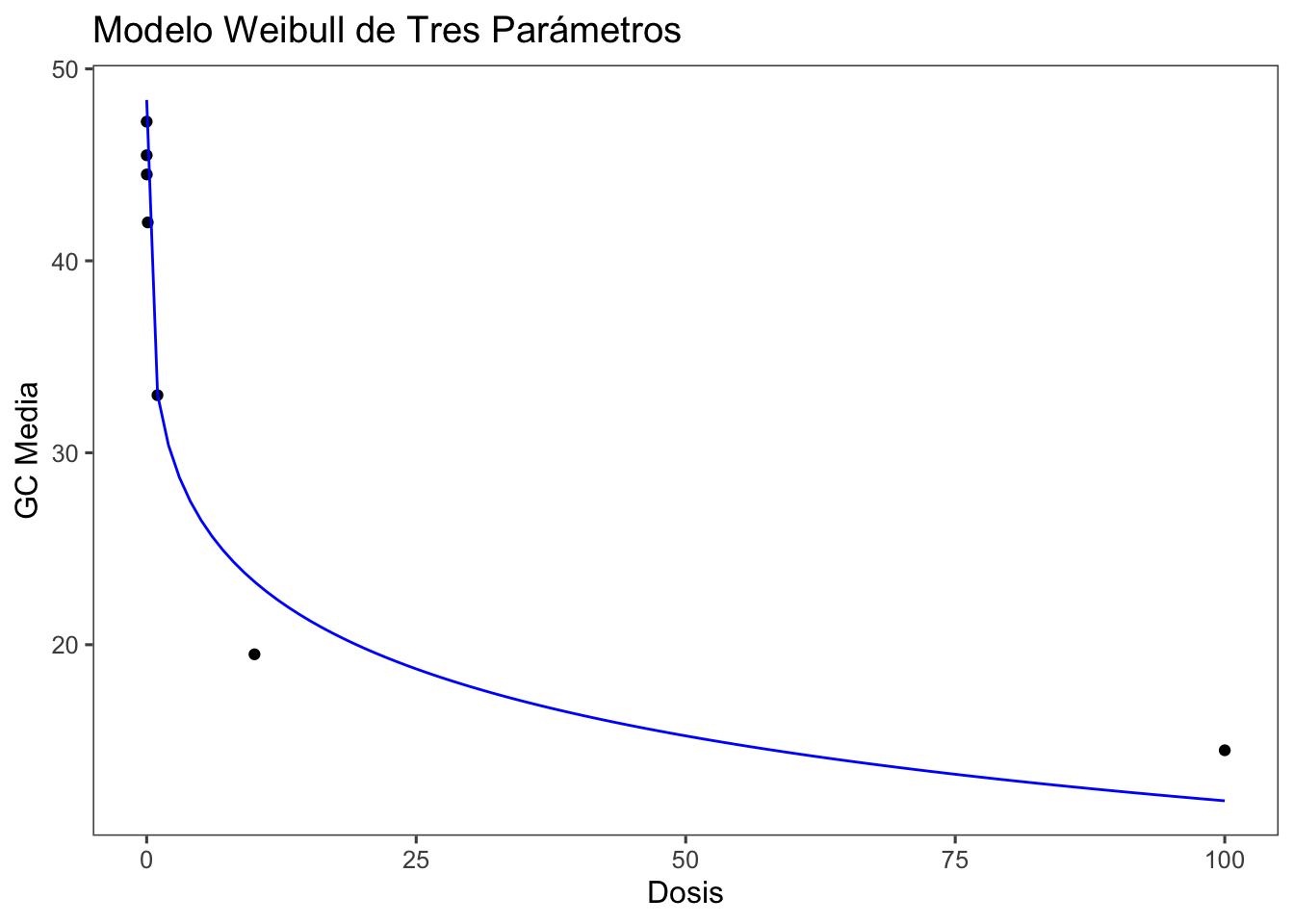
ec50estimatorEstimamos los valores de EC50 para diferentes identificadores (ID).
# Estimar EC50
df_ec50 <- estimate_EC50(GC_mean ~ Dose, data = dat2, isolate_col = "Code", interval = "delta", fct = drc::LL.3())
df_ec50 |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))|>
formatRound(c('Estimate','Std..Error','Lower','Upper'), 2)df_ec50El dataframe df_ec50 generalmente incluye las siguientes columnas:
# Crear gráfico de estimaciones de EC50
df_ec50 |>
ggplot(aes(Estimate, reorder(ID, Estimate))) +
geom_point() +
geom_errorbar(aes(xmin = Lower, xmax = Upper), width = 0.1) +
scale_x_continuous(breaks = seq(from = -30, to = 50, by = 5))+
labs(title = "Estimaciones de EC50 por Código", x = "EC50", y = "Aislamiento") +
theme_few()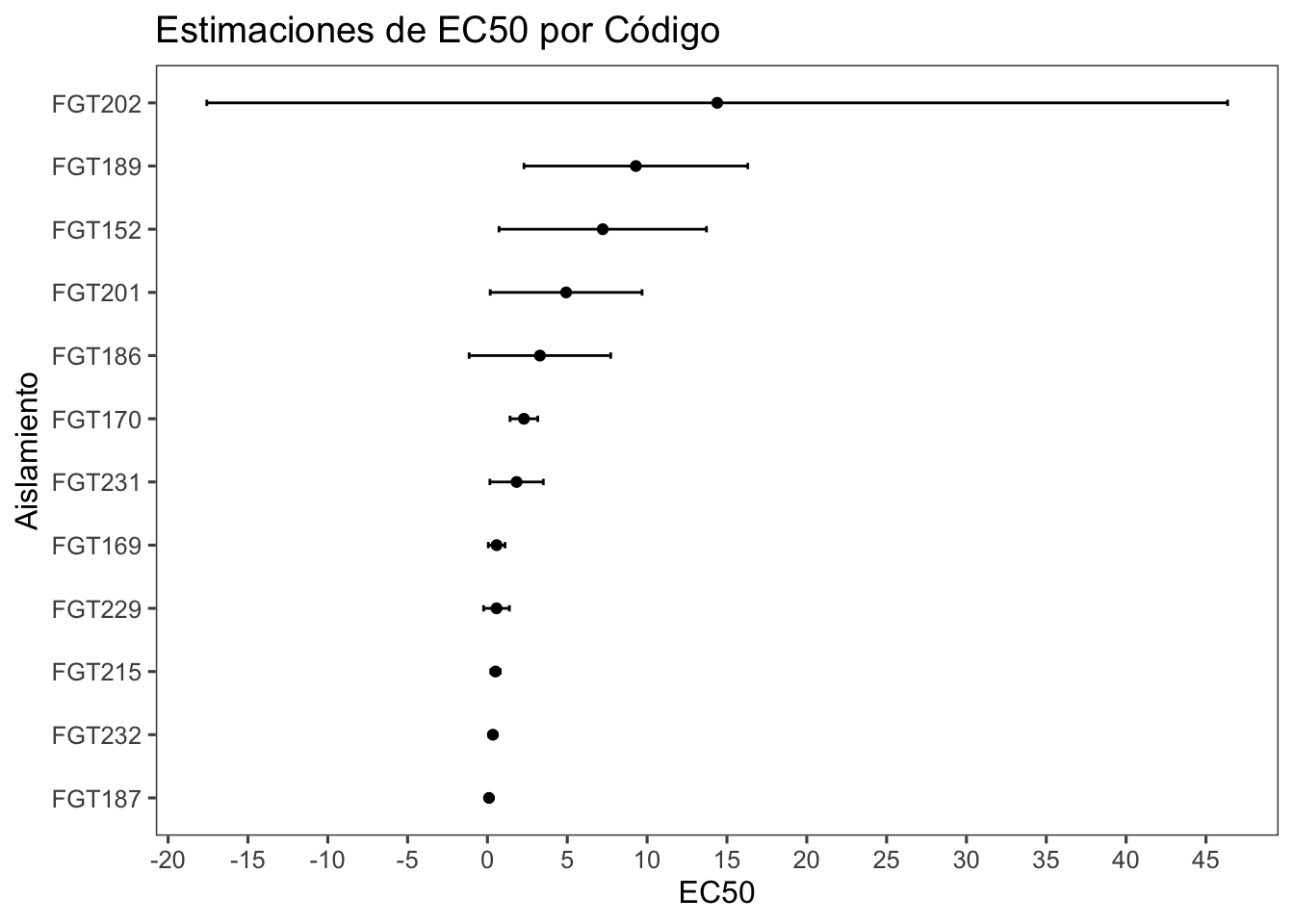
En el gráfico resultante:
El análisis de regresión no lineal es una herramienta poderosa para modelar relaciones complejas entre variables. Con RStudio y los paquetes adecuados, podemos realizar análisis detallados y obtener estimaciones precisas que informen mejor nuestras decisiones basadas en datos. La utilización de ggplot2 para la visualización de los resultados permite una interpretación más clara y efectiva de los modelos ajustados.