Codigo
library(readxl)
library(tidyverse)
library(dplyr)
library(ggplot2)
library(ggthemes)
library(DT)En esta guía, aprenderás cómo realizar análisis de varianza (ANOVA) en RStudio paso a paso, utilizando diferentes diseños experimentales y comprobando las premisas estadísticas necesarias.
La ANOVA (Análisis de Varianza) es un método estadístico que permite comparar las medias de tres o más grupos y verificar si hay diferencias significativas entre ellas. Utiliza el test F para probar la hipótesis nula de que las medias poblacionales son iguales contra la hipótesis alternativa de que al menos una media es diferente.
Un experimento con un factor en un diseño completamente aleatorizado para comparar el crecimiento micelial de diferentes especies de un hongo fitopatógeno. La respuesta a estudiar es la TCM (tasa de crecimiento micelial). Pregunta a responder: ¿Hay efecto de la especie en el crecimiento micelial?
Cargamento de Paquetes e Importación de los Datos
library(readxl)
library(tidyverse)
library(dplyr)
library(ggplot2)
library(ggthemes)
library(DT)# Cargar los datos desde un archivo Excel
micelial <- read_excel("dados-diversos.xlsx", "micelial")
micelial |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))micelial %>%
ggplot(aes(especie, tcm, fill = especie)) +
geom_boxplot()+
theme_few()+
scale_fill_few()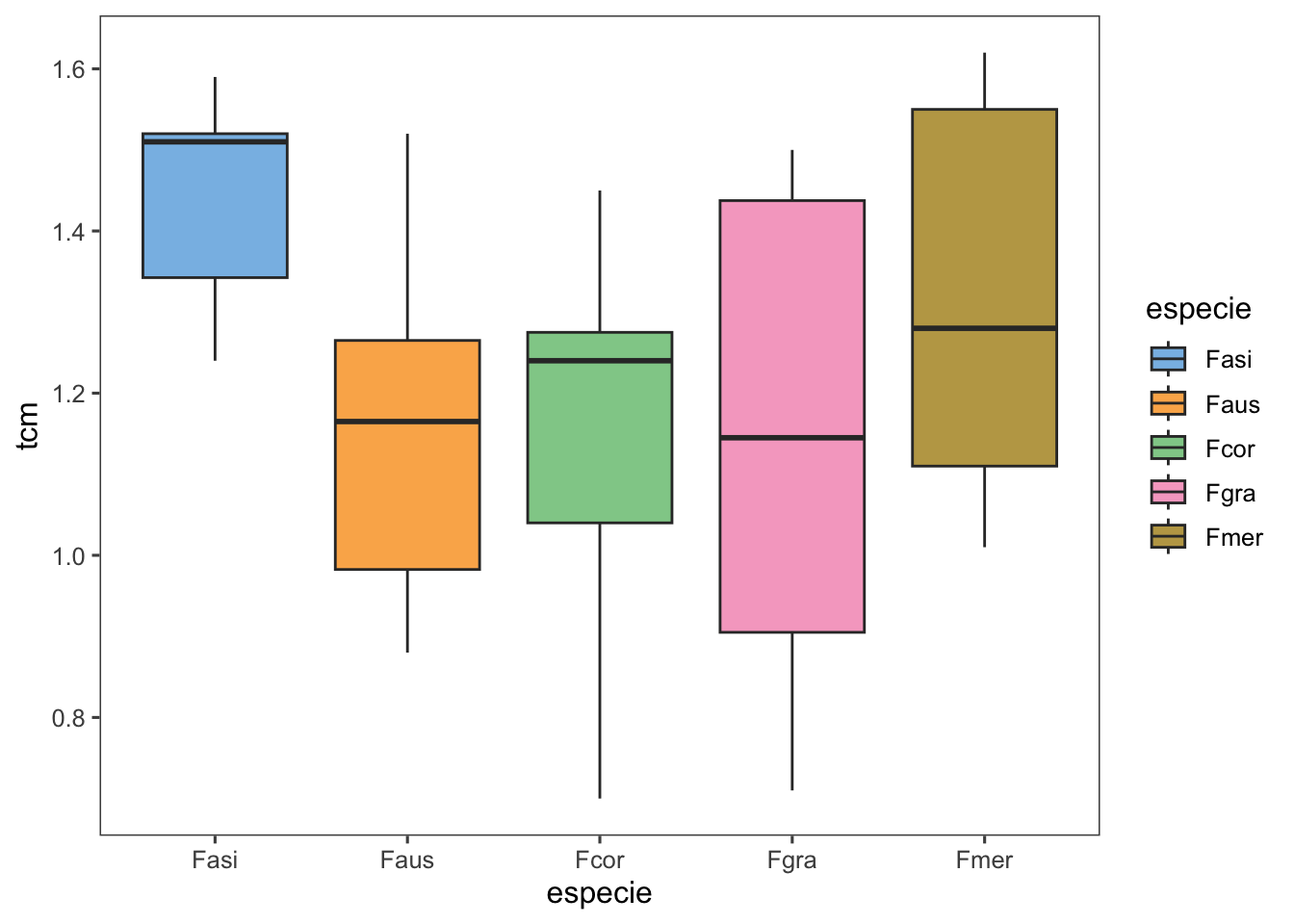
aov()# Crear el modelo ANOVA
aov1 <- aov(tcm ~ especie, data = micelial)
# Resumen del modelo
summary(aov1) Df Sum Sq Mean Sq F value Pr(>F)
especie 4 0.4692 0.11729 1.983 0.117
Residuals 37 2.1885 0.05915 Interpretación: En este conjunto de datos, no hay diferencia significativa en la media micelial (no hay efecto significativo de la especie sobre el crecimiento micelial).
Para probar las premisas, cargamos los paquetes performance y DHARMa.
library(performance)
library(DHARMa)
# Chequear homocedasticidad y normalidad
check_heteroscedasticity(aov1)OK: Error variance appears to be homoscedastic (p = 0.175).check_normality(aov1)OK: residuals appear as normally distributed (p = 0.074).Interpretación de la Homocedasticidad: Si la prueba muestra que la homocedasticidad se cumple, significa que las variancias de los residuos son constantes. Si no, se podría considerar transformar los datos o usar una técnica alternativa.
Interpretación de la Normalidad: La normalidad de los residuos se puede visualizar con un histograma y un gráfico QQ.
# Visualización de los residuos
hist(aov1$residuals)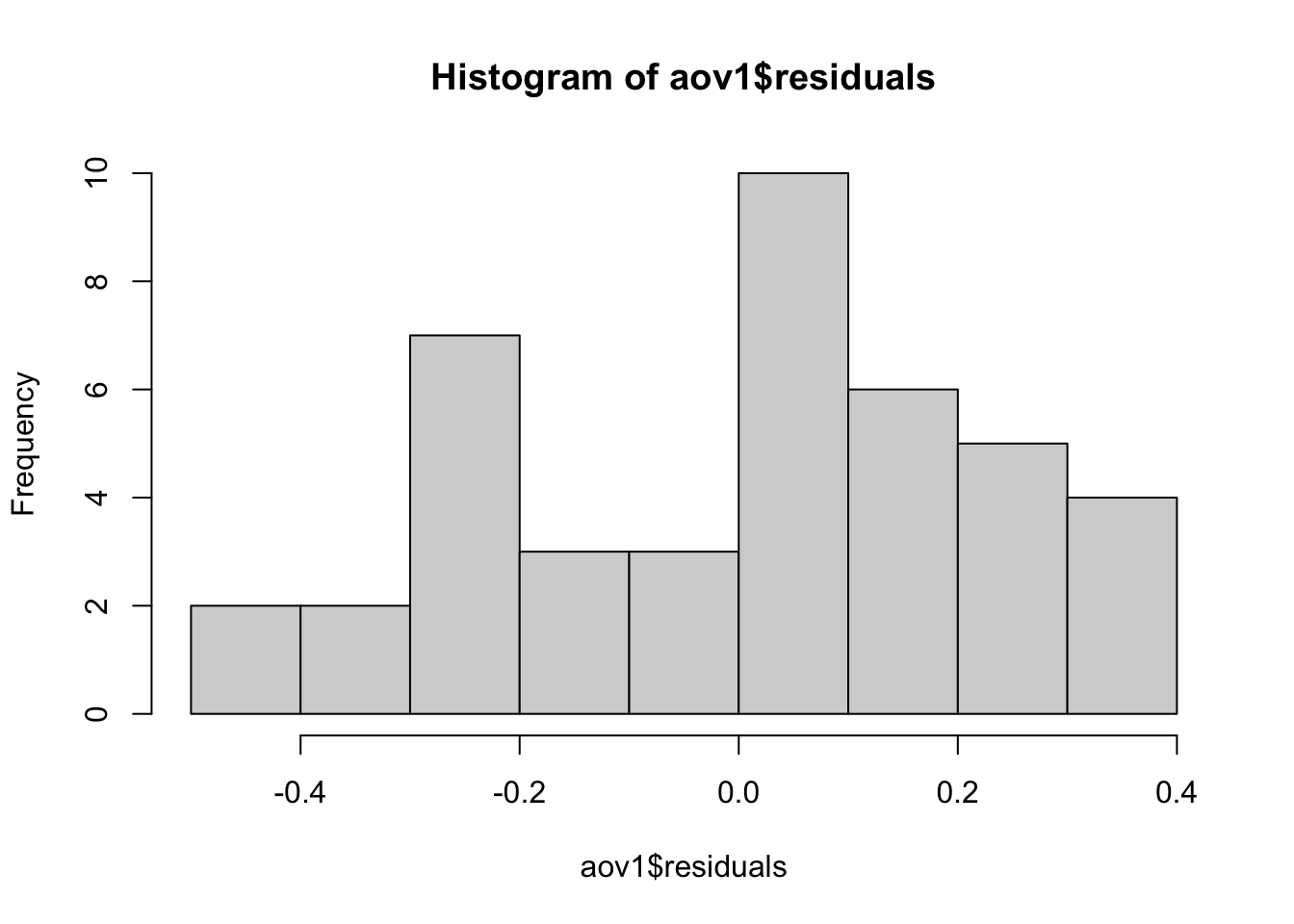
# Gráfico QQ
qqnorm(aov1$residuals)
qqline(aov1$residuals)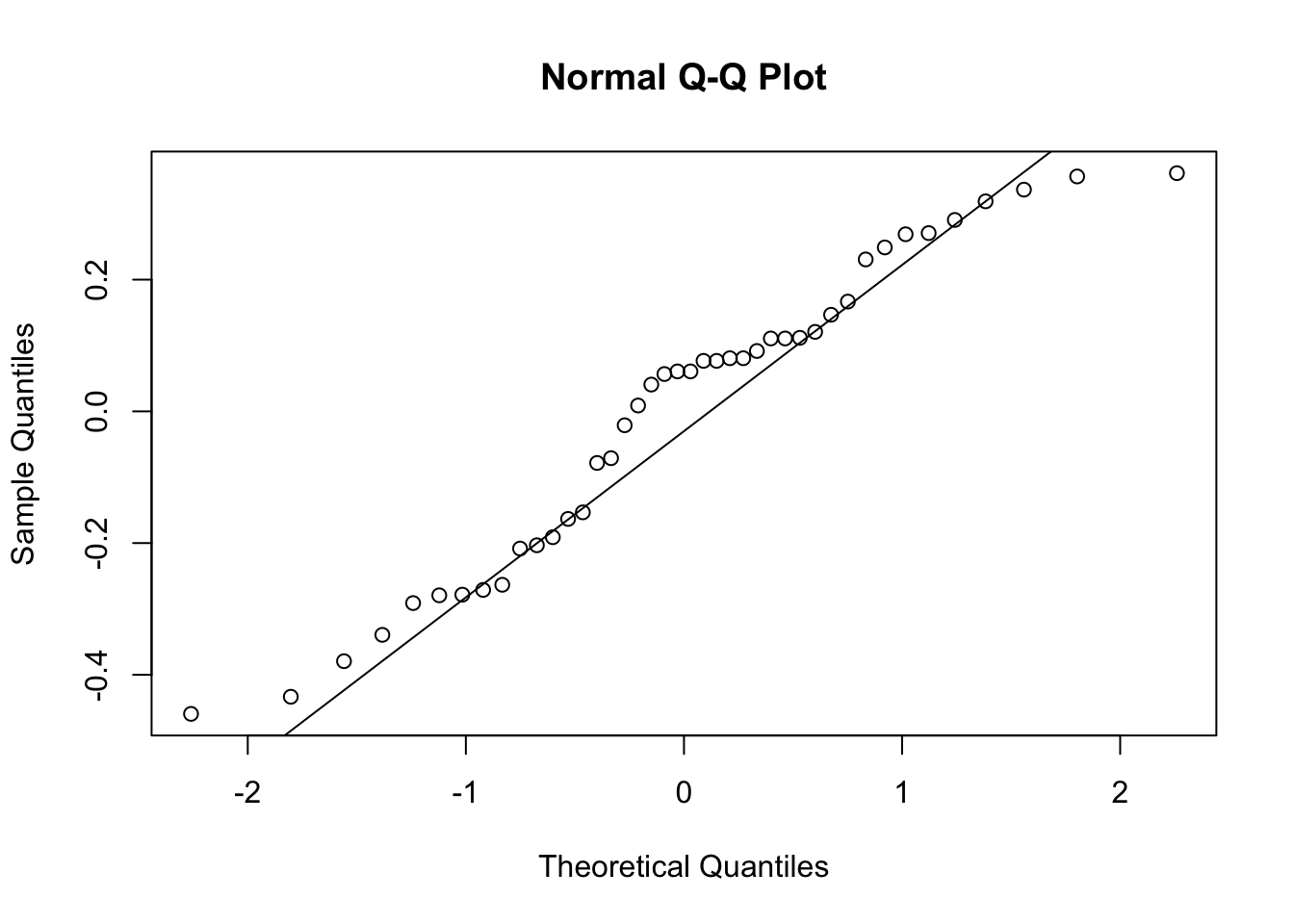
# Simulación de residuos
plot(simulateResiduals(aov1))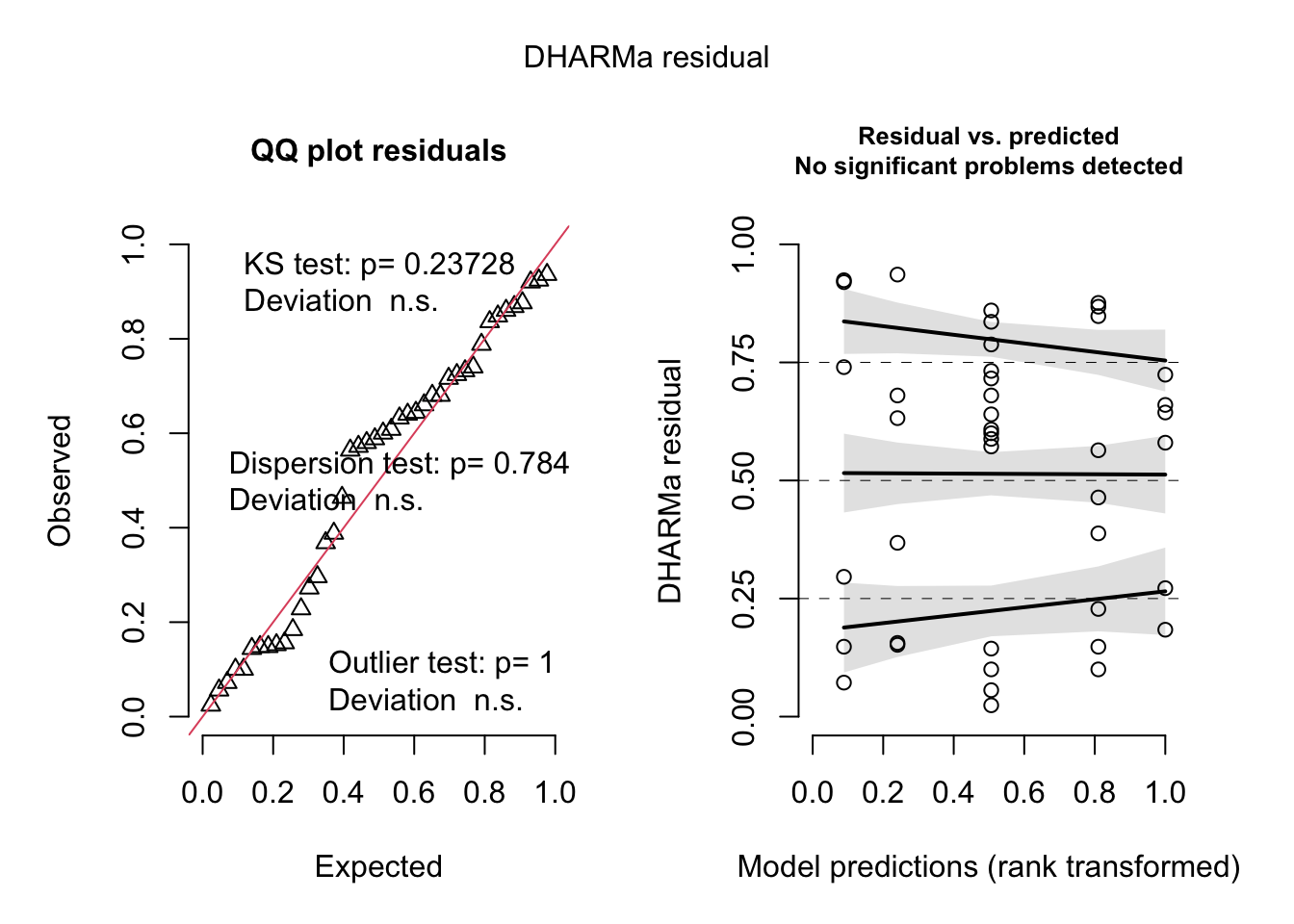
# Test de Shapiro-Wilk para normalidad
shapiro.test(aov1$residuals)
Shapiro-Wilk normality test
data: aov1$residuals
W = 0.95101, p-value = 0.07022Interpretación del Test de Shapiro-Wilk: Si el p-valor es mayor que 0.05, no se rechaza la hipótesis nula de que los residuos siguen una distribución normal. Si es menor, se rechaza la hipótesis nula, sugiriendo que los residuos no son normales.
Conjunto InsectSprays: efecto del insecticida en la mortalidad de insectos (Beall, 1942). Datos en el paquete datasets de R.
# Cargar los datos del conjunto InsectSprays
insects <- tibble::as_tibble(InsectSprays) %>%
dplyr::select(spray, count)
insects |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))insects |>
ggplot(aes(spray, count,fill = spray)) +
geom_boxplot()+
theme_few()+
scale_fill_few()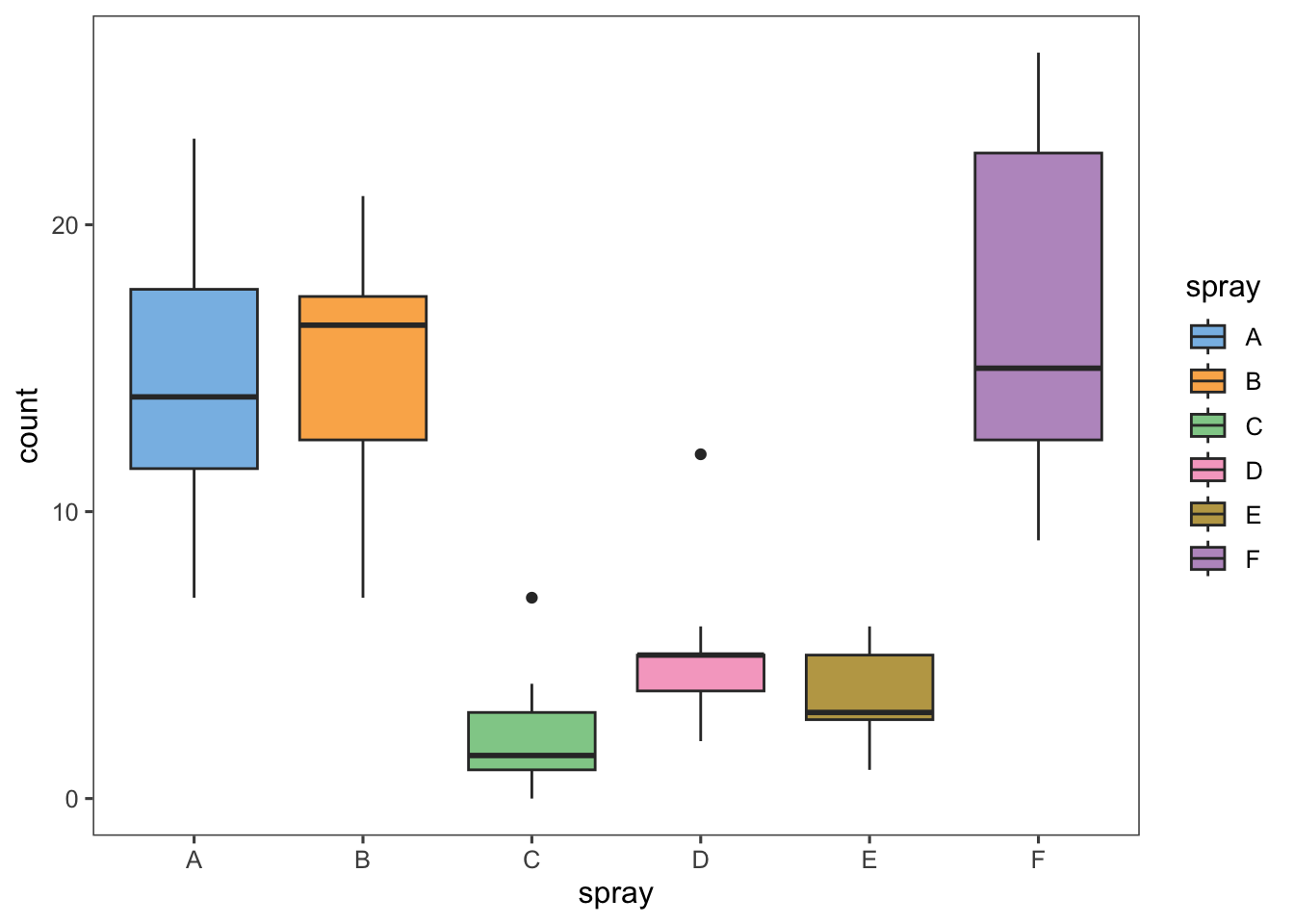
aov2 <- aov(count ~ spray, data = insects)
summary(aov2) Df Sum Sq Mean Sq F value Pr(>F)
spray 5 2669 533.8 34.7 <2e-16 ***
Residuals 66 1015 15.4
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1check_normality(aov2)Warning: Non-normality of residuals detected (p = 0.022).check_heteroscedasticity(aov2)Warning: Heteroscedasticity (non-constant error variance) detected (p < .001).Interpretación: Los datos no son normales y homogéneos.
aov2 <- aov(sqrt(count) ~ spray, data = insects)
summary(aov2) Df Sum Sq Mean Sq F value Pr(>F)
spray 5 88.44 17.688 44.8 <2e-16 ***
Residuals 66 26.06 0.395
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1check_normality(aov2)OK: residuals appear as normally distributed (p = 0.681).check_heteroscedasticity(aov2)OK: Error variance appears to be homoscedastic (p = 0.854).Interpretación: Si la transformación logra normalizar los datos y cumplir la homocedasticidad, se puede proceder con la ANOVA transformada. Si no, se deben considerar otras alternativas.
# Test de Kruskal-Wallis
kruskal.test(count ~ spray, data = insects)
Kruskal-Wallis rank sum test
data: count by spray
Kruskal-Wallis chi-squared = 54.691, df = 5, p-value = 1.511e-10# Test de Kruskal-Wallis con el paquete agricolae
library(agricolae)
kruskal(insects$count, insects$spray, console = TRUE)
Study: insects$count ~ insects$spray
Kruskal-Wallis test's
Ties or no Ties
Critical Value: 54.69134
Degrees of freedom: 5
Pvalue Chisq : 1.510845e-10
insects$spray, means of the ranks
insects.count r
A 52.16667 12
B 54.83333 12
C 11.45833 12
D 25.58333 12
E 19.33333 12
F 55.62500 12
Post Hoc Analysis
t-Student: 1.996564
Alpha : 0.05
Minimum Significant Difference: 8.462804
Treatments with the same letter are not significantly different.
insects$count groups
F 55.62500 a
B 54.83333 a
A 52.16667 a
D 25.58333 b
E 19.33333 bc
C 11.45833 cInterpretación del Test de Kruskal-Wallis: Este test no requiere la asunción de normalidad. Si el p-valor es menor que 0.05, hay diferencias significativas entre los grupos.
emmeansEl paquete emmeans es usado para realizar pruebas de comparación de medias entre grupos.
library(emmeans)
# Calcular medias marginales estimadas
aov2_means <- emmeans(aov2, ~ spray, type = "response")
aov2_means spray response SE df lower.CL upper.CL
A 14.14 1.364 66 11.550 17.00
B 15.03 1.406 66 12.352 17.97
C 1.55 0.452 66 0.779 2.58
D 4.68 0.785 66 3.248 6.38
E 3.27 0.656 66 2.095 4.72
F 16.15 1.458 66 13.370 19.19
Confidence level used: 0.95
Intervals are back-transformed from the sqrt scale # Tabla de comparación de medias
pwpm(aov2_means) A B C D E F
A [14.14] 0.9975 <.0001 <.0001 <.0001 0.9145
B -0.116 [15.03] <.0001 <.0001 <.0001 0.9936
C 2.516 2.632 [ 1.55] 0.0081 0.2513 <.0001
D 1.596 1.712 -0.919 [ 4.68] 0.7366 <.0001
E 1.951 2.067 -0.565 0.355 [ 3.27] <.0001
F -0.258 -0.142 -2.774 -1.854 -2.209 [16.15]
Row and column labels: spray
Upper triangle: P values adjust = "tukey"
Diagonal: [Estimates] (response) type = "response"
Lower triangle: Comparisons (estimate) earlier vs. later# Forma mas eficiente de realizar medias marginales estimadas y Visualización de las diferencias entre grupos
library(multcomp)
library(multcompView)
aov2_means<- cld(emmeans(aov2, ~ spray, type = "response"),alpha = 0.05, Letters = LETTERS,reverse=T)
aov2_means|>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv"))) |>
formatRound(c('response','SE','lower.CL','upper.CL'), 2)Para modelos lineales generalizados, usamos la función glm.
glm1 <- glm(count ~ spray, data = insects, family = poisson(link = "identity"))
# Visualización de los residuos
plot(simulateResiduals(glm1))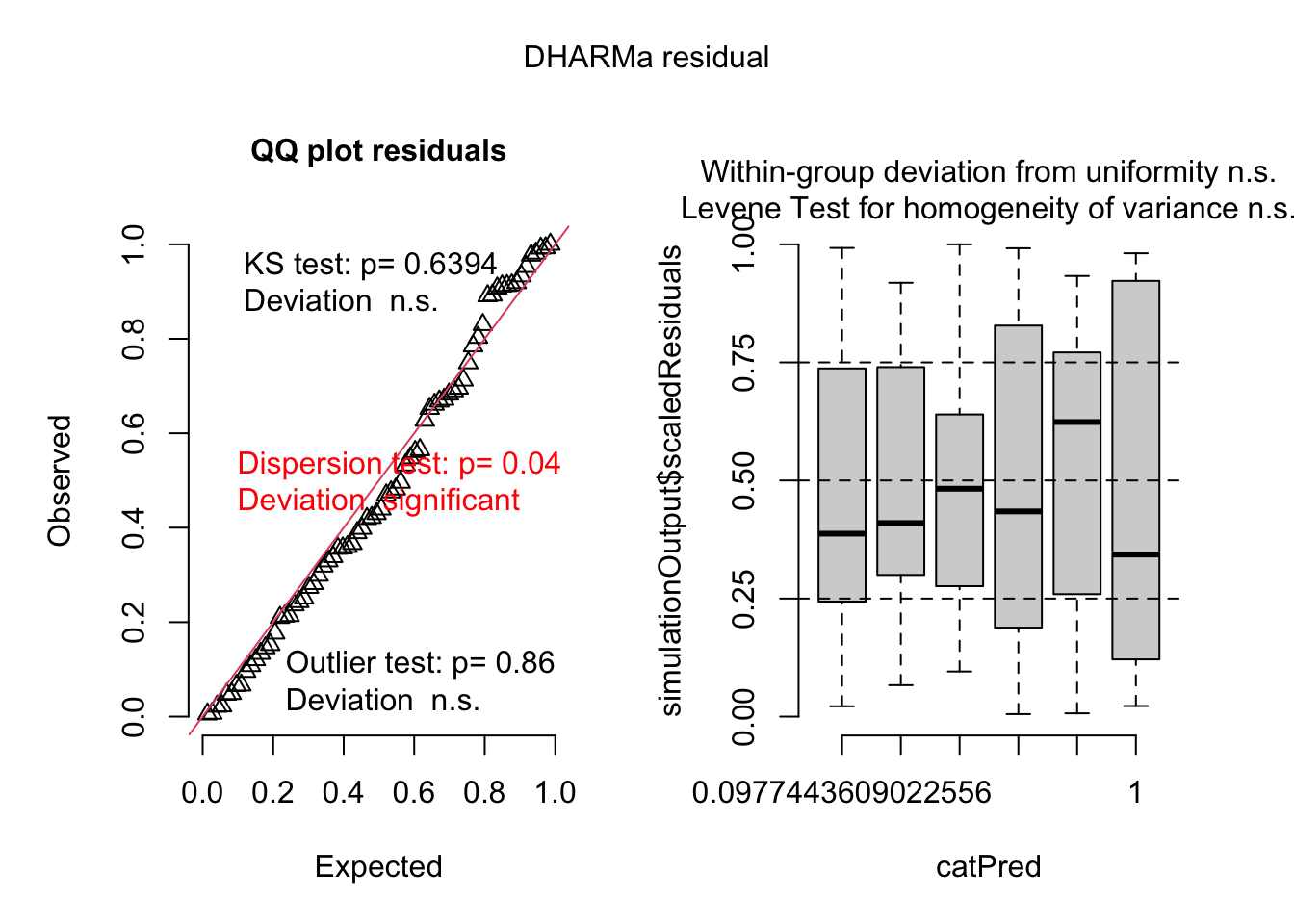
summary(glm1)
Call:
glm(formula = count ~ spray, family = poisson(link = "identity"),
data = insects)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 14.5000 1.0992 13.191 < 2e-16 ***
sprayB 0.8333 1.5767 0.529 0.597
sprayC -12.4167 1.1756 -10.562 < 2e-16 ***
sprayD -9.5833 1.2720 -7.534 4.92e-14 ***
sprayE -11.0000 1.2247 -8.981 < 2e-16 ***
sprayF 2.1667 1.6116 1.344 0.179
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 409.041 on 71 degrees of freedom
Residual deviance: 98.329 on 66 degrees of freedom
AIC: 376.59
Number of Fisher Scoring iterations: 3# Calcular medias marginales estimadas para el GLM
glm1_means <- emmeans(glm1, ~ spray)
cld(glm1_means) spray emmean SE df asymp.LCL asymp.UCL .group
C 2.08 0.417 Inf 1.27 2.90 1
E 3.50 0.540 Inf 2.44 4.56 12
D 4.92 0.640 Inf 3.66 6.17 2
A 14.50 1.099 Inf 12.35 16.65 3
B 15.33 1.130 Inf 13.12 17.55 3
F 16.67 1.179 Inf 14.36 18.98 3
Confidence level used: 0.95
P value adjustment: tukey method for comparing a family of 6 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same. performance y DHARMa para estas pruebas.emmeans facilita la comparación de medias ajustadas y es útil tanto para ANOVA como para GLM.