En esta guía, aprenderás cómo realizar análisis de varianza (ANOVA) en RStudio paso a paso, utilizando diferentes diseños experimentales y comprobando las premisas estadísticas necesarias.
ANOVA con Bloques Completamente Aleatorizados (DBC)
Preparación Pre-Análisis
Cargar Paquetes y Cargar Datos
Primero, cargamos los paquetes necesarios y luego importamos nuestros datos desde un archivo Excel.
En el diseño de bloques completamente aleatorizados, usamos el símbolo + para incluir el efecto del bloque.
Codigo
aov_fung <-aov(sev ~ trat + rep, data = fungicidas)summary(aov_fung)
Df Sum Sq Mean Sq F value Pr(>F)
trat 7 7135 1019.3 287.661 <2e-16 ***
rep 1 19 18.6 5.239 0.0316 *
Residuals 23 81 3.5
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
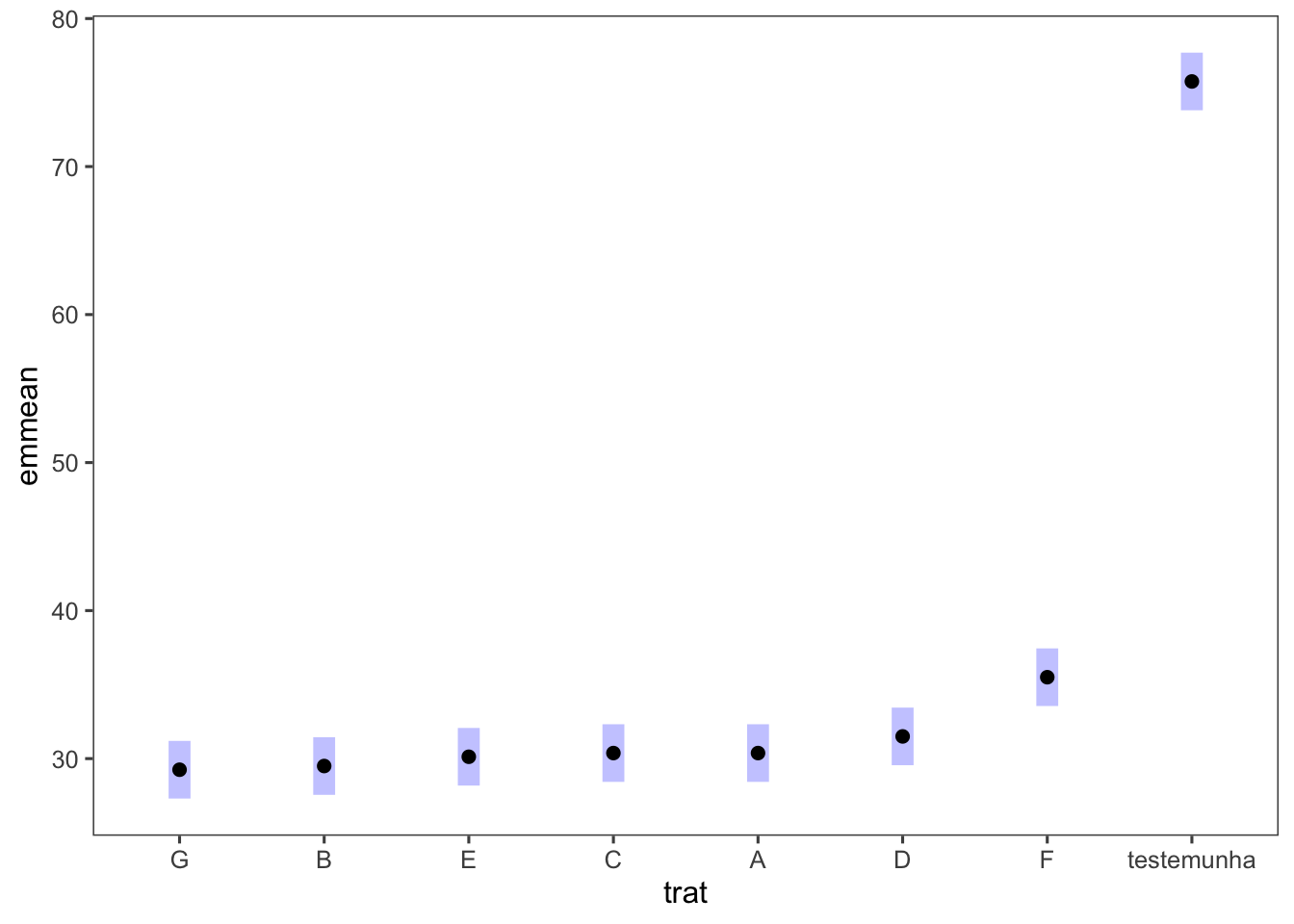
Interpretación de Resultados: - El resumen nos muestra los estadísticos F, los p-valores y las medias para cada tratamiento y bloque. - Si un p-valor es menor que 0.05, hay evidencia suficiente para rechazar la hipótesis nula de que las medias son iguales.
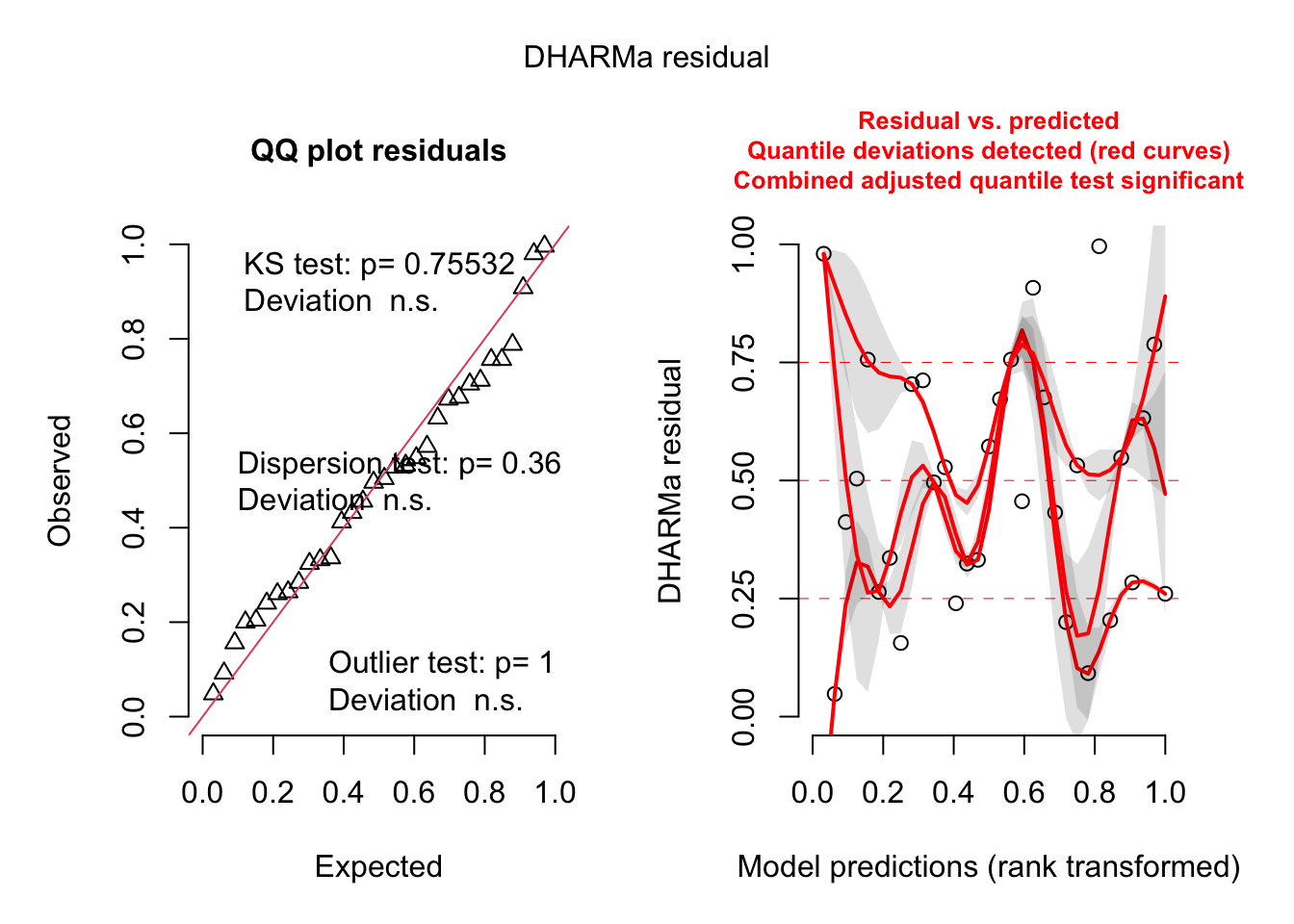
Chequeo de Premisas
Utilizamos performance y DHARMa para verificar la normalidad y homogeneidad de varianzas de los residuos.
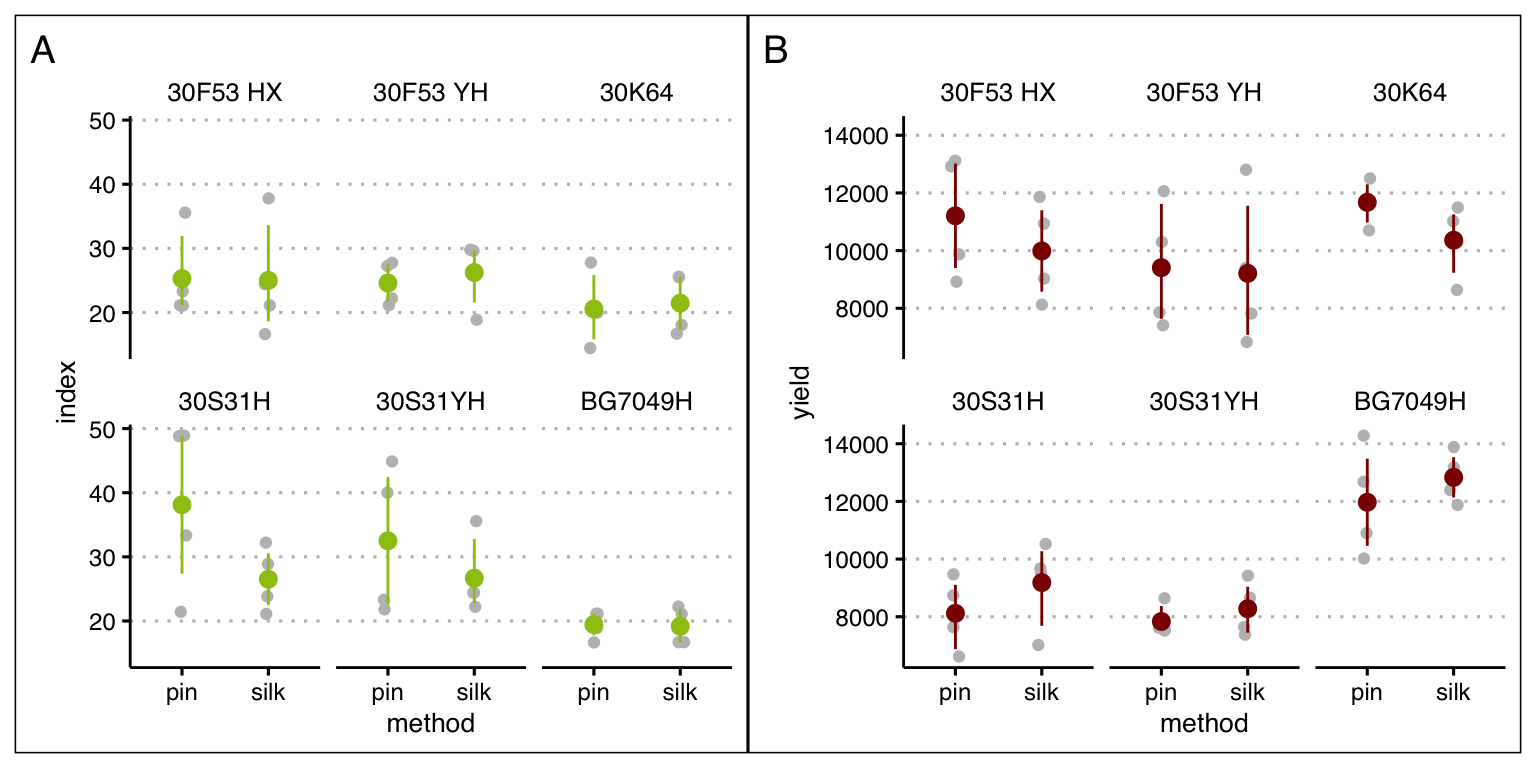
Para un diseño de parcela subdividida, especificamos el efecto del bloque y las interacciones.
Codigo
aov_milho_bloco <-aov(index ~factor(block) + hybrid*method +Error(factor(block)/hybrid/method), data = milho)summary(aov_milho_bloco)
Error: factor(block)
Df Sum Sq Mean Sq
factor(block) 3 592.2 197.4
Error: factor(block):hybrid
Df Sum Sq Mean Sq F value Pr(>F)
hybrid 5 974.2 194.84 3.14 0.0389 *
Residuals 15 930.9 62.06
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: factor(block):hybrid:method
Df Sum Sq Mean Sq F value Pr(>F)
method 1 79.61 79.61 4.726 0.0433 *
hybrid:method 5 265.28 53.06 3.150 0.0324 *
Residuals 18 303.18 16.84
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Interpretación de Resultados: - El modelo ANOVA nos proporciona información sobre las interacciones entre el bloque, el híbrido y el método, así como los efectos principales.
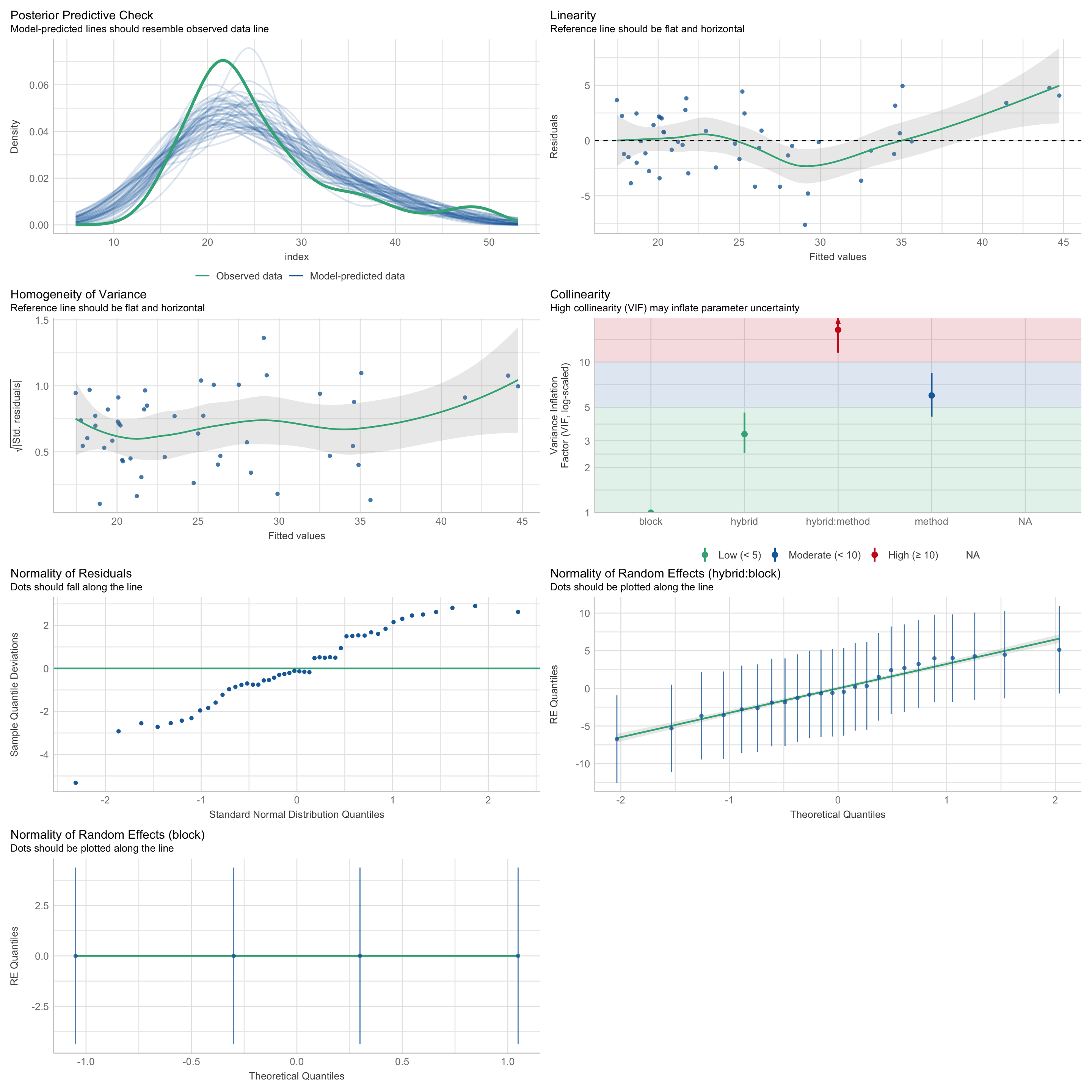
Chequeo de Premisas con Modelo Mixto (lme4)
En parcelas subdivididas, usamos modelos mixtos para comprobar las premisas estadísticas.
Codigo
library(lme4)library(car)# Convertir el bloque en factormilho$block <-as.factor(milho$block)mix2 <-lmer(index ~ block + hybrid*method + (1|block/hybrid), data = milho)Anova(mix2)
# Si queremos comparar métodos dentro de cada híbrido:# means_mix2 <- emmeans(mix2, ~ method | hybrid)
Aprendizaje del día
Esta guía te ha mostrado cómo realizar análisis de varianza (ANOVA) en RStudio para diferentes diseños experimentales, desde bloques completamente aleatorizados hasta parcelas subdivididas. Utilizando paquetes como tidyverse, readxl, performance, DHARMa, emmeans, multcomp, multcompView, lme4 y car, puedes realizar análisis estadísticos avanzados y asegurarte de cumplir con las premisas necesarias para interpretar correctamente tus resultados.
Source Code
# Análisis de Varianza (ANOVA) En esta guía, aprenderás cómo realizar análisis de varianza (ANOVA) en RStudio paso a paso, utilizando diferentes diseños experimentales y comprobando las premisas estadísticas necesarias.# ANOVA con Bloques Completamente Aleatorizados (DBC)## Preparación Pre-Análisis### Cargar Paquetes y Cargar DatosPrimero, cargamos los paquetes necesarios y luego importamos nuestros datos desde un archivo Excel.```{r}# Cargar paquetes necesarioslibrary(tidyverse)library(readxl)library(DT)library(patchwork)library(lme4)# Importar datos: fungicida_campo desde el archivo dados-diversos.xlsxfungicidas <-read_excel("dados-diversos.xlsx", sheet ="fungicida_campo")fungicidas|> DT::datatable(extensions ='Buttons', options =list(dom ='Bfrtip', buttons =c('excel', "csv")))```### Modelo ANOVA con BloqueEn el diseño de bloques completamente aleatorizados, usamos el símbolo `+` para incluir el efecto del bloque.```{r}aov_fung <-aov(sev ~ trat + rep, data = fungicidas)summary(aov_fung)```**Interpretación de Resultados**:- El resumen nos muestra los estadísticos F, los p-valores y las medias para cada tratamiento y bloque.- Si un p-valor es menor que 0.05, hay evidencia suficiente para rechazar la hipótesis nula de que las medias son iguales.### Chequeo de PremisasUtilizamos `performance` y `DHARMa` para verificar la normalidad y homogeneidad de varianzas de los residuos.```{r}library(performance)library(DHARMa)check_normality(aov_fung)``````{r}check_heteroscedasticity(aov_fung)``````{r}plot(simulateResiduals(aov_fung))```### Estimación de MediasCalculamos las medias de los tratamientos usando `emmeans` y mostramos las diferencias significativas con `cld`.```{r}library(emmeans)library(multcomp)library(multcompView)means_fung<-cld(emmeans(aov_fung, ~trat),alpha =0.05, Letters = LETTERS,reverse=F)means_fung|> DT::datatable(extensions ='Buttons', options =list(dom ='Bfrtip', buttons =c('excel', "csv"))) |>formatRound(c('emmean','SE','lower.CL','upper.CL'), 2)``````{r}# Visualización gráfica de las mediaslibrary(ggthemes)plot(means_fung) +coord_flip() +theme_few()```## Diseño en Parcela Subdividida (Split-plot)### Preparación Pre-Análisis: Importación de DatosImportamos los datos del conjunto de datos de milho para un diseño en parcela subdividida.```{r}milho <-read_excel("dados-diversos.xlsx", sheet ="milho")milho|> DT::datatable(extensions ='Buttons', options =list(dom ='Bfrtip', buttons =c('excel', "csv"))) |>formatRound('index', 2)```### visualizar indx e produtividade```{r}index <- milho |>ggplot(aes(method,index))+geom_jitter(width =0.05, colour="gray")+stat_summary(fun.data ="mean_cl_boot",color="#9cc414")+facet_wrap(~hybrid)+theme_clean()Prod<- milho |>ggplot(aes(method,yield))+geom_jitter(width =0.05, colour="gray")+stat_summary(fun.data ="mean_cl_boot",color="#8b0000")+facet_wrap(~hybrid)+theme_clean()``````{r,fig.width=8, fig.height=4,fig.fullwidth=TRUE}(index | Prod ) + plot_layout(guides = "collect" )+ plot_annotation(tag_levels = "A")```### Ajuste del Modelo ANOVAPara un diseño de parcela subdividida, especificamos el efecto del bloque y las interacciones.```{r}aov_milho_bloco <-aov(index ~factor(block) + hybrid*method +Error(factor(block)/hybrid/method), data = milho)summary(aov_milho_bloco)```**Interpretación de Resultados**:- El modelo ANOVA nos proporciona información sobre las interacciones entre el bloque, el híbrido y el método, así como los efectos principales.### Chequeo de Premisas con Modelo Mixto (lme4)En parcelas subdivididas, usamos modelos mixtos para comprobar las premisas estadísticas.```{r}library(lme4)library(car)# Convertir el bloque en factormilho$block <-as.factor(milho$block)mix2 <-lmer(index ~ block + hybrid*method + (1|block/hybrid), data = milho)Anova(mix2)``````{r}check_normality(mix2)``````{r}check_heteroscedasticity(mix2)``````{r, fig.width=15, fig.height=15, fig.fullwidth=TRUE}check_model(mix2)```### Transformación de Datos para Cumplir PremisasSi los datos no cumplen con las premisas, consideramos transformaciones como la raíz cuadrada.```{r}milho$block <-as.factor(milho$block)mix2 <-lmer(sqrt(index) ~ block + hybrid*method + (1|block/hybrid), data = milho)Anova(mix2)``````{r}check_normality(mix2)``````{r}check_heteroscedasticity(mix2)```### Comparación de MediasCalculamos y comparamos las medias utilizando `emmeans` para cada interacción de híbrido y método.```{r}means_mix2<-cld(emmeans(mix2, ~hybrid | method),alpha =0.05, Letters = LETTERS,reverse=T)means_mix2|> DT::datatable(extensions ='Buttons', options =list(dom ='Bfrtip', buttons =c('excel', "csv"))) |>formatRound(c('emmean','SE','df','lower.CL','upper.CL'), 2)# Si queremos comparar métodos dentro de cada híbrido:# means_mix2 <- emmeans(mix2, ~ method | hybrid)```## Aprendizaje del díaEsta guía te ha mostrado cómo realizar análisis de varianza (ANOVA) en RStudio para diferentes diseños experimentales, desde bloques completamente aleatorizados hasta parcelas subdivididas. Utilizando paquetes como `tidyverse`, `readxl`, `performance`, `DHARMa`, `emmeans`, `multcomp`, `multcompView`, `lme4` y `car`, puedes realizar análisis estadísticos avanzados y asegurarte de cumplir con las premisas necesarias para interpretar correctamente tus resultados.