Codigo
library(tidyverse)
library(dplyr)
library(readxl)
library(ggplot2)
library(janitor)
library(epifitter)
library(performance)
library(emmeans)
library(DT)
library(ggthemes)Una tabla de contingencia, también conocida como tabla de frecuencia cruzada, es una herramienta fundamental en el análisis estadístico que se utiliza para:
Considera un estudio sobre la presencia de especies de fusarium en diferentes tipos de residuos de cultivos. Supongamos que tenemos datos sobre el tipo de residuo utilizado (variable residue) y el tipo de especie de fusarium (variable species). Una tabla de contingencia nos permitiría ver cuántas veces se ha encontrado cada tipo de especie de fusarium en cada tipo de residuo de cultivo, lo cual es esencial para analizar si hay alguna preferencia o patrón de crecimiento entre diferentes residuos de cultivos.
library(tidyverse)
library(dplyr)
library(readxl)
library(ggplot2)
library(janitor)
library(epifitter)
library(performance)
library(emmeans)
library(DT)
library(ggthemes)Primero, cargamos los datos desde un archivo Excel:
survey <- read_excel("dados-diversos.xlsx", sheet = "survey")
survey|>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))Utilizamos la función table() para crear una tabla de contingencia:
q <- table(survey$residue, survey$species)
q |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))Al observar la tabla de contingencia, podemos: - Verificar las frecuencias de cada combinación de residue y species. - Evaluar si ciertos especies de fusarium predominan en ciertos cultivos. - Identificar si hay alguna combinación de residue y species que es particularmente común o rara.
Utilizamos la función adorn_percentages() del paquete janitor para obtener porcentajes:
survey1<-survey |>
tabyl(year, species) |>
adorn_percentages()
survey1 |>
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv")))|>
formatRound(c('Fgra','Fspp'), 2)Podemos visualizar la tabla de contingencia con un gráfico de barras:
survey |>
filter(residue != "NA") |>
count(residue, species) |>
ggplot(aes(residue, n, fill = species)) +
geom_col() +
labs(title = "Distribución de Residuos por Especies",
x = "Residuos",
y = "Frecuencia",
fill = "Especies")+
theme_few()+
scale_fill_few()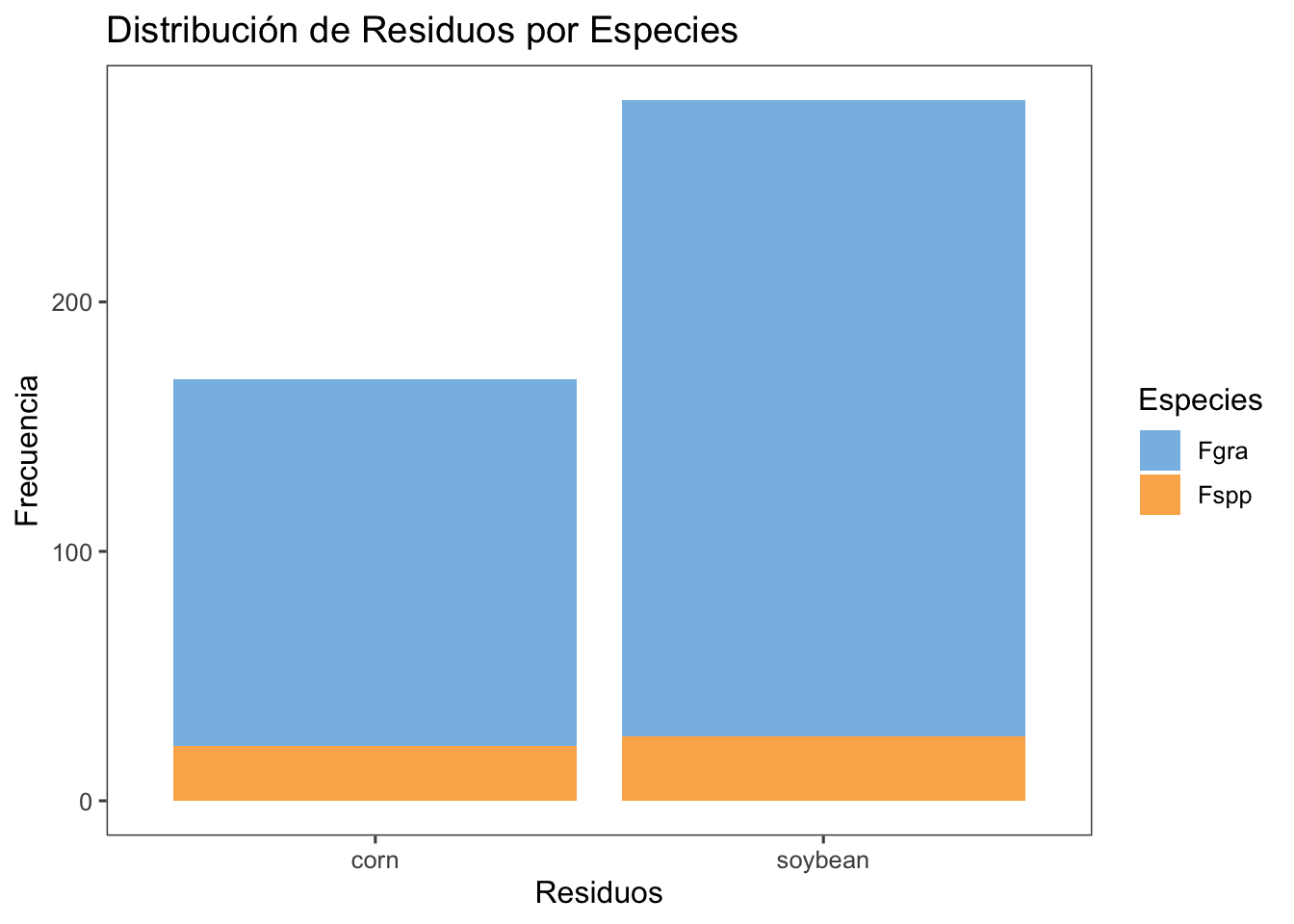
El test de chi-cuadrado se utiliza para evaluar la independencia entre dos variables categóricas:
chisq.test(q)
Pearson's Chi-squared test with Yates' continuity correction
data: q
X-squared = 1.1997, df = 1, p-value = 0.2734Este test nos dirá si la asociación observada entre el tipo de cultivo y el tipo de especie de fusarium es significativa, ayudándonos a entender si existe una relación no aleatoria entre estas variables.
Para tablas de contingencia 2x2 o con pocas observaciones, utilizamos el test de Fisher:
q <- table(survey$residue, survey$inc_class)
fisher.test(q)
Fisher's Exact Test for Count Data
data: q
p-value = 0.09855
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.4492084 1.0721250
sample estimates:
odds ratio
0.696718