Codigo
library(tidyverse)
library(readxl)
fungicida_campo <- read_excel("dados-diversos.xlsx", "fungicida_campo")Este script en R se centra en la visualización y análisis de datos utilizando diversas técnicas gráficas. A continuación se explica paso a paso cada sección del script, resaltando las funciones importantes utilizadas y su propósito.
Primero, se importan los datos desde un archivo de Excel utilizando la función read_excel() del paquete readxl. Los datos se leen desde la hoja “fungicida_campo” del archivo “dados-diversos.xlsx” y se asignan al data frame fungicida_campo.
library(tidyverse)
library(readxl)
fungicida_campo <- read_excel("dados-diversos.xlsx", "fungicida_campo")Los scatterplots son gráficos que muestran la relación entre dos variables numéricas. Se utilizan para identificar patrones o correlaciones entre ellas.
geom_jitter() y stat_summary()En este bloque de código, se crea un scatterplot que muestra la dispersión de los datos de sev (severidad) versus trat (tratamiento), con puntos distribuidos de manera jittered para evitar superposiciones y se añade la media utilizando stat_summary().
fungicida_campo |>
ggplot(aes(trat, sev)) +
geom_jitter(width = 0.1, color = "gray60") +
stat_summary(fun = mean, color = "red")+
theme_few() 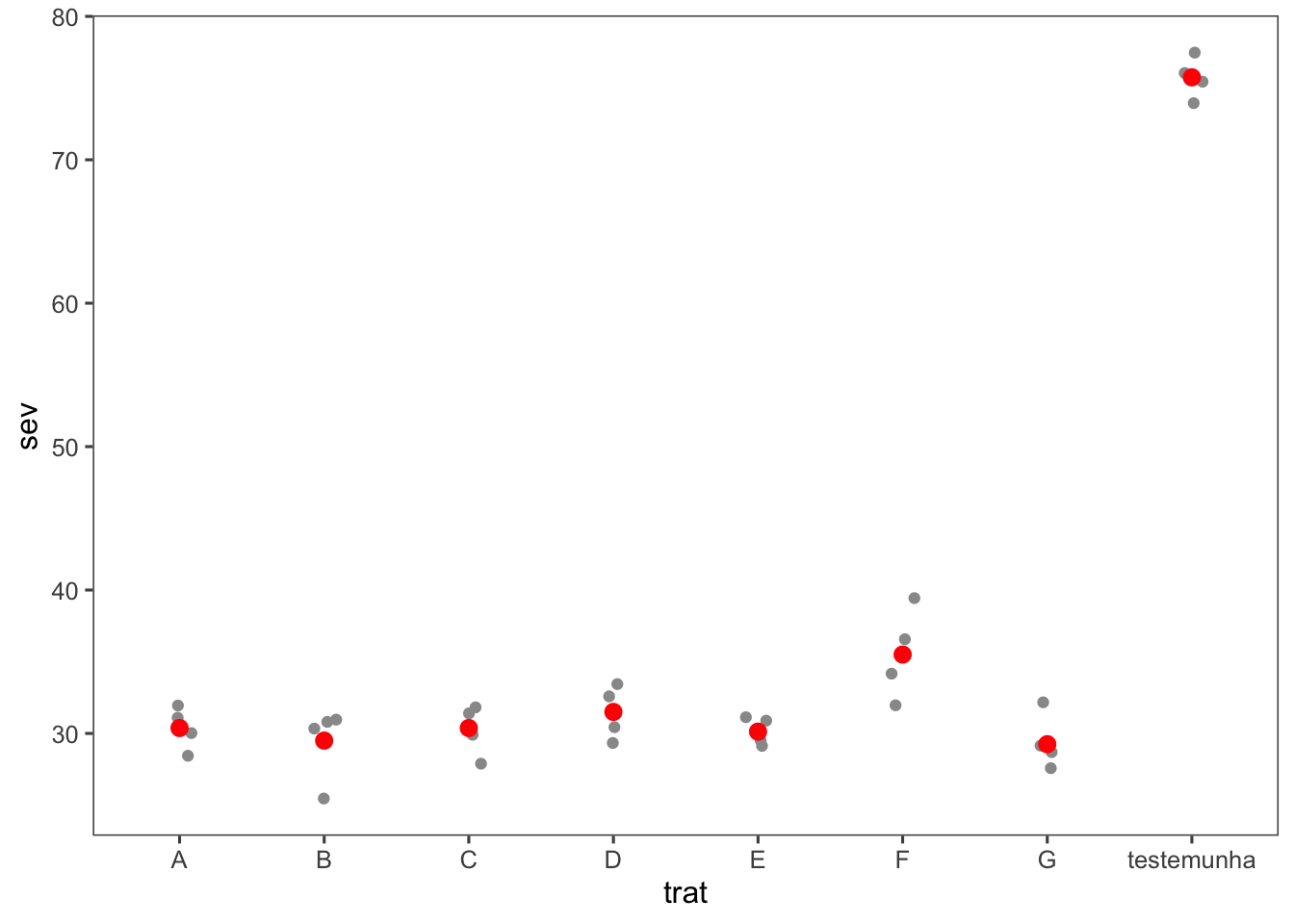
Este scatterplot añade un intervalo de confianza alrededor de la media utilizando stat_summary() con fun.data = mean_se.
fungicida_campo |>
ggplot(aes(trat, sev)) +
geom_jitter(width = 0.1, color = "gray60") +
stat_summary(fun.data = mean_se, color = "red")+
theme_few()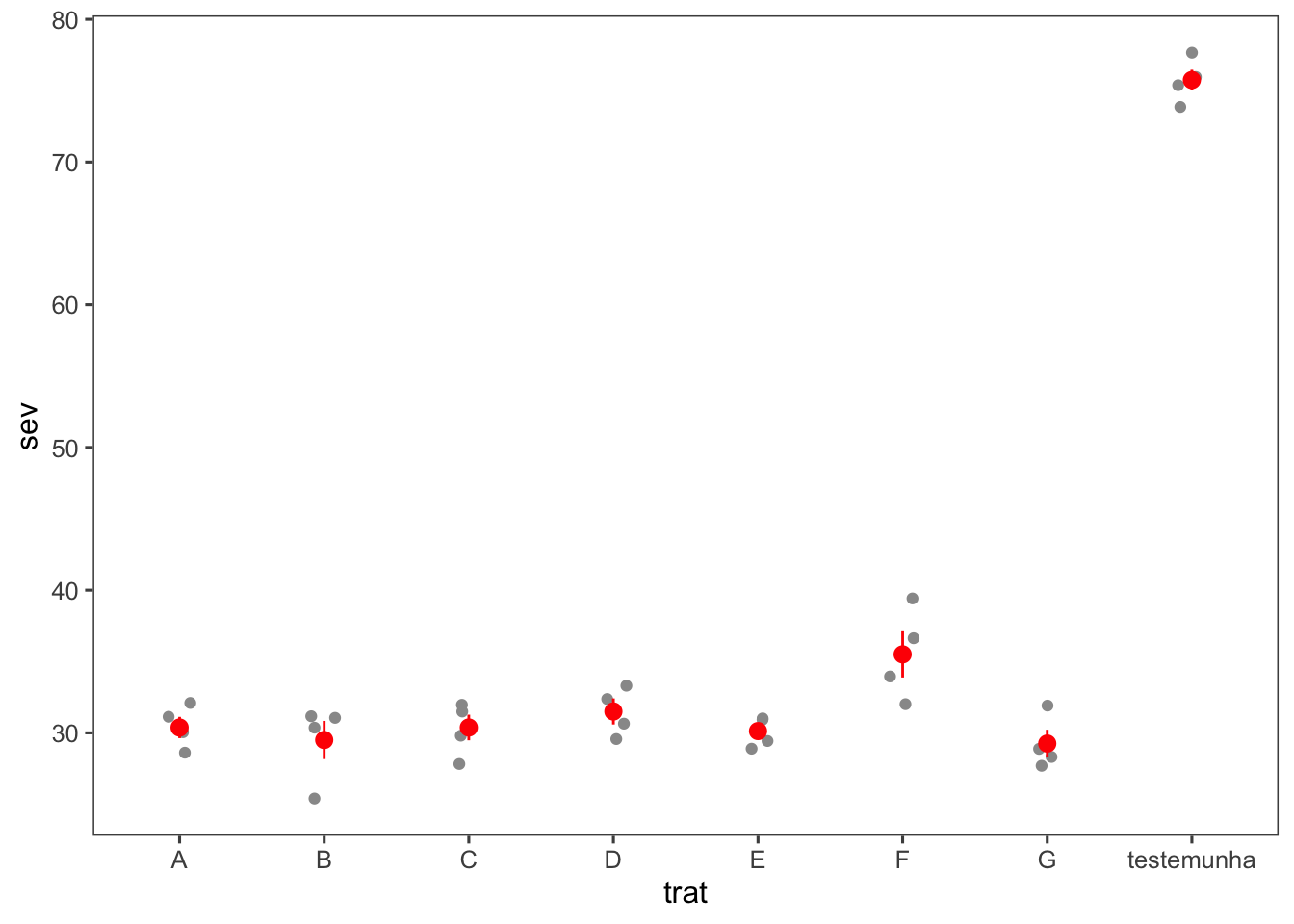
En este ejemplo, se cambia la variable sev al eje x y yld (rendimiento) al eje y, y se colorea por trat utilizando scale_color_colorblind(). Además, se ajusta la transparencia de los puntos usando alpha.
library(ggthemes)
fungicida_campo |>
ggplot(aes(sev, yld, color = trat)) +
geom_point(size = 3, alpha = 0.8) +
scale_color_colorblind()+
theme_few()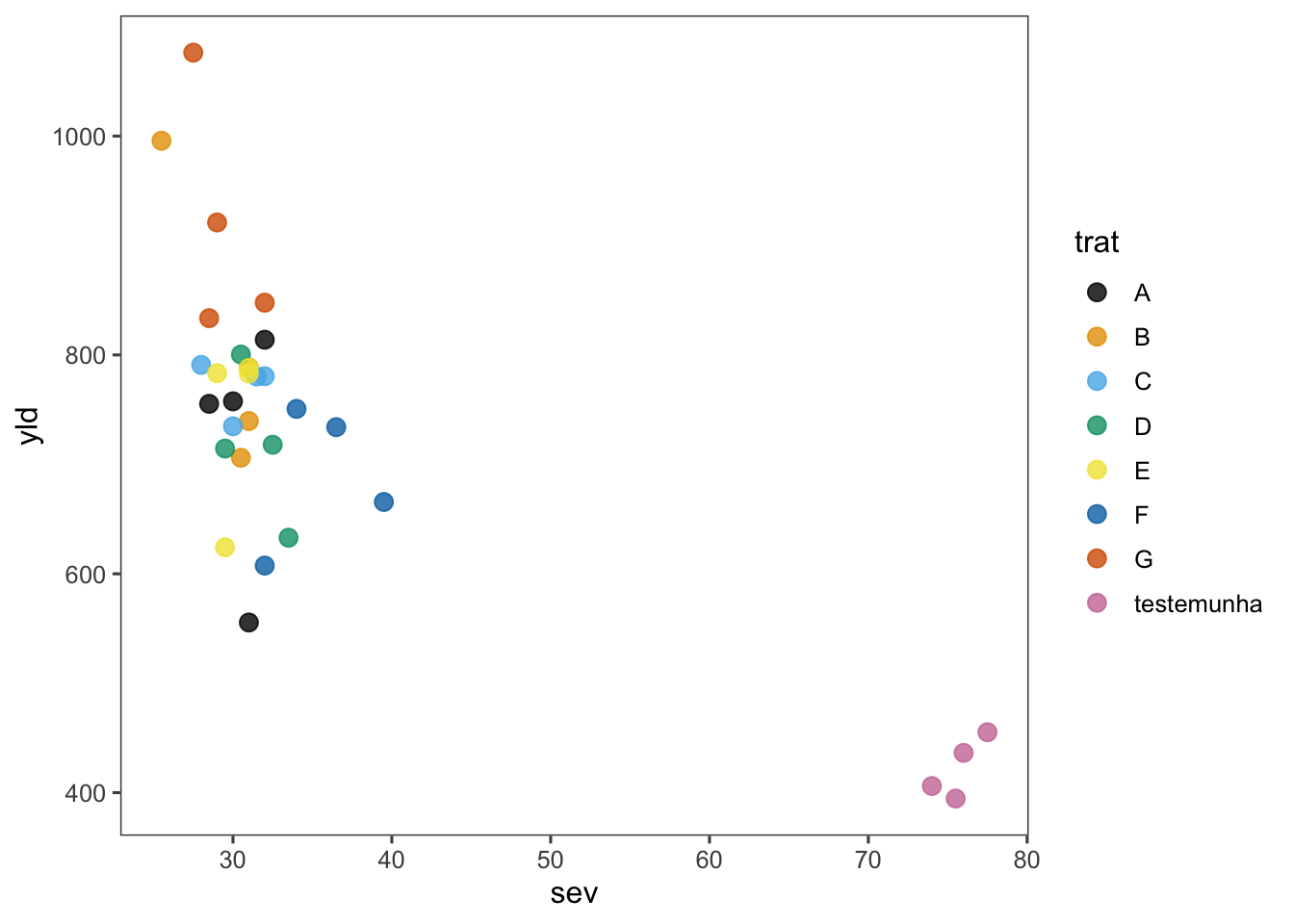
Aquí se añade una línea de tendencia lineal utilizando geom_smooth() con method = "lm" y se = FALSE para eliminar la visualización del intervalo de confianza.
fungicida_campo |>
ggplot(aes(sev, yld)) +
geom_point(size = 3, alpha = 0.8) +
geom_smooth(method = "lm", se = FALSE, color = "black", linetype = "solid", size = 2) +
scale_color_colorblind()+
theme_few()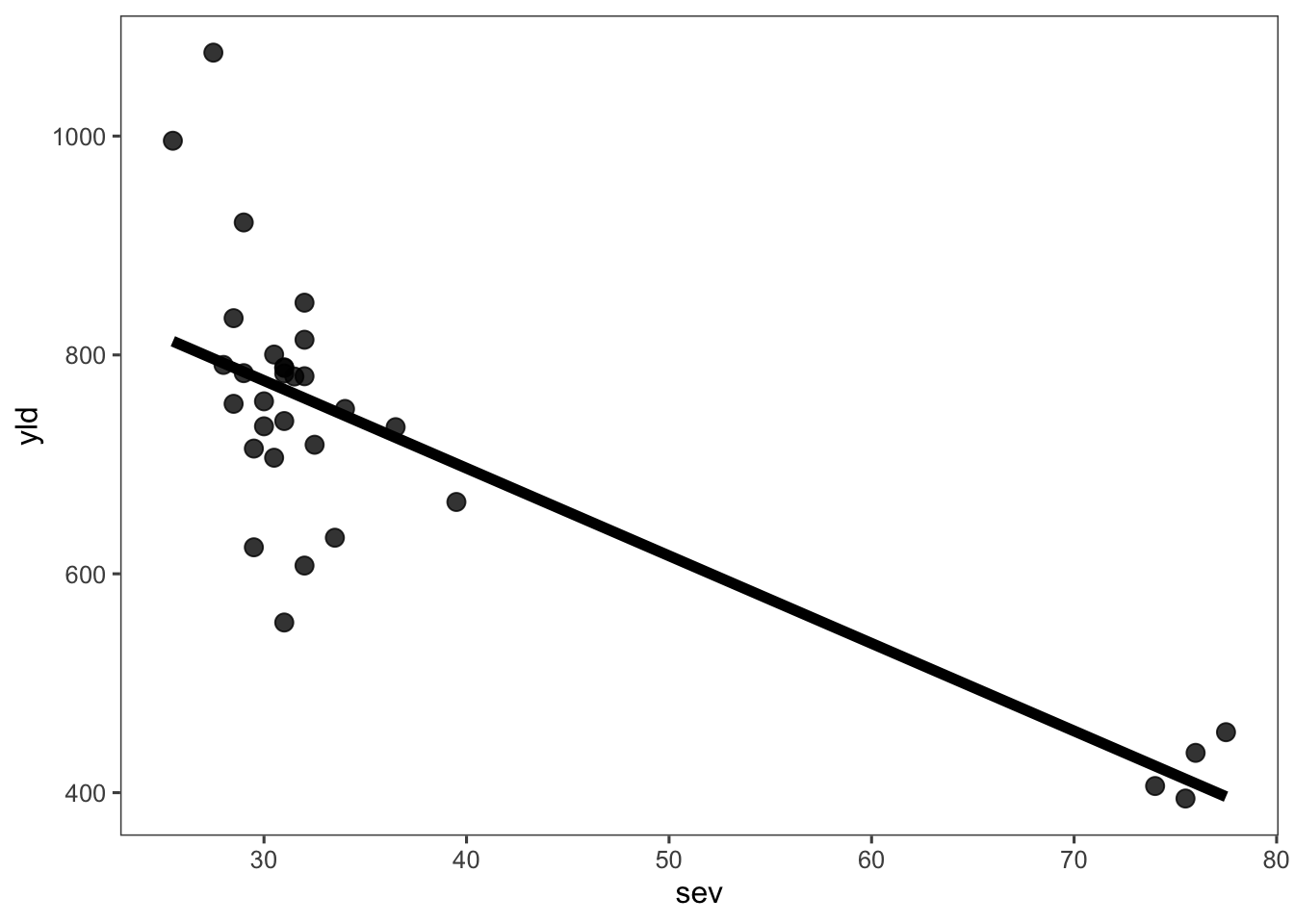
En esta sección, se cambia el subconjunto de datos a milho y se crea un scatterplot que muestra la variación del rendimiento (yield) de diferentes híbridos de maíz (hybrid) según el método de inoculación (method). Se utiliza facet_wrap() para separar los gráficos por hybrid.
milho <- read_excel("dados-diversos.xlsx", "milho")
milho |>
ggplot(aes(hybrid, yield, color = method)) +
geom_jitter(size = 2) +
facet_wrap(~hybrid)+
theme_few()+
scale_color_few()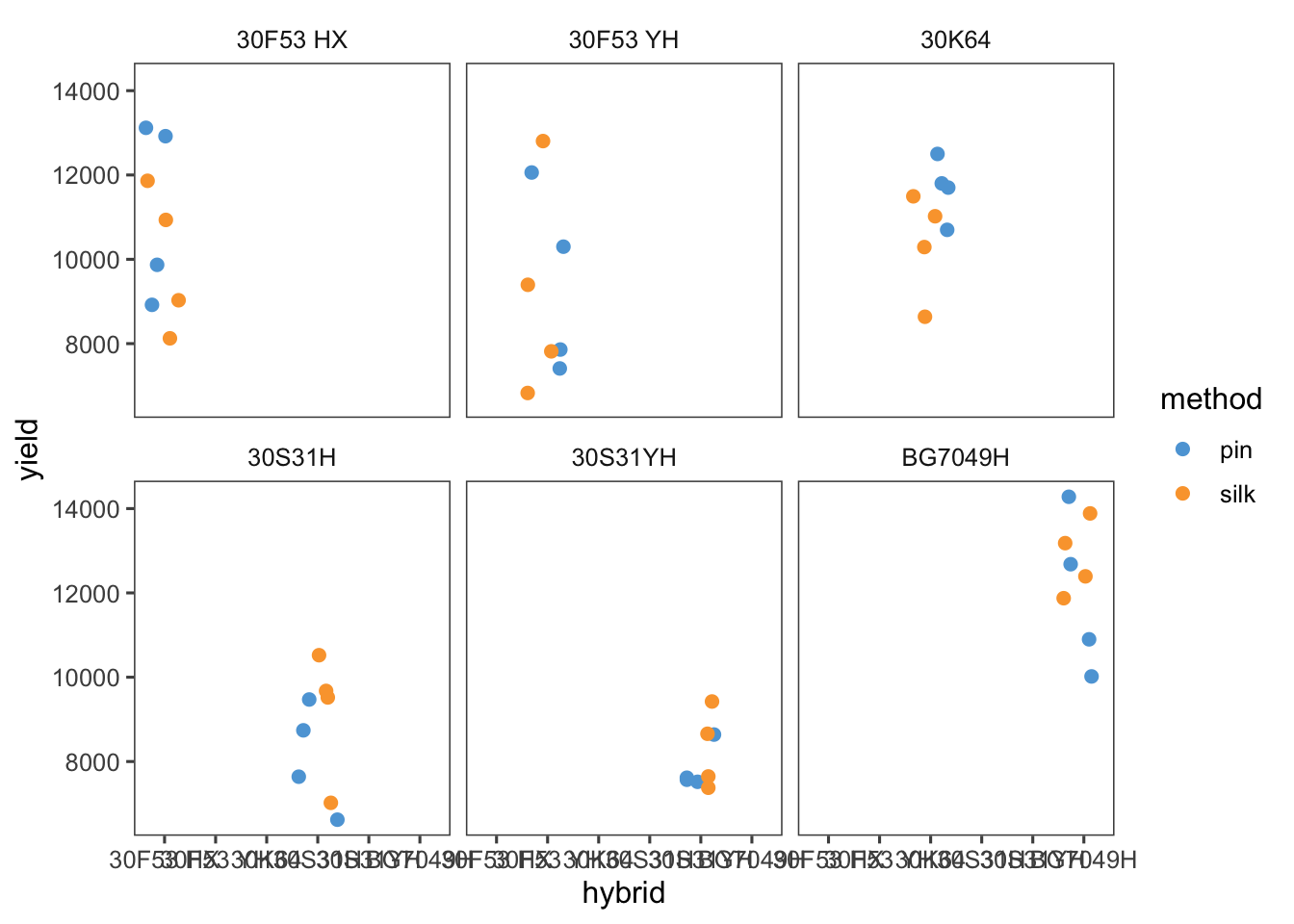
Los histogramas se utilizan para visualizar la distribución de una variable numérica. Se construyen con geom_histogram().
yieldEn este ejemplo, se crea un histograma para la variable yield con 10 bins, y se cambia el color del borde (color) y el color de relleno (fill) de las barras.
p_yield <- milho |>
ggplot(aes(x = yield)) +
geom_histogram(bins = 10, color = "black", fill = "green")+
theme_few()+
scale_color_few()
p_yield 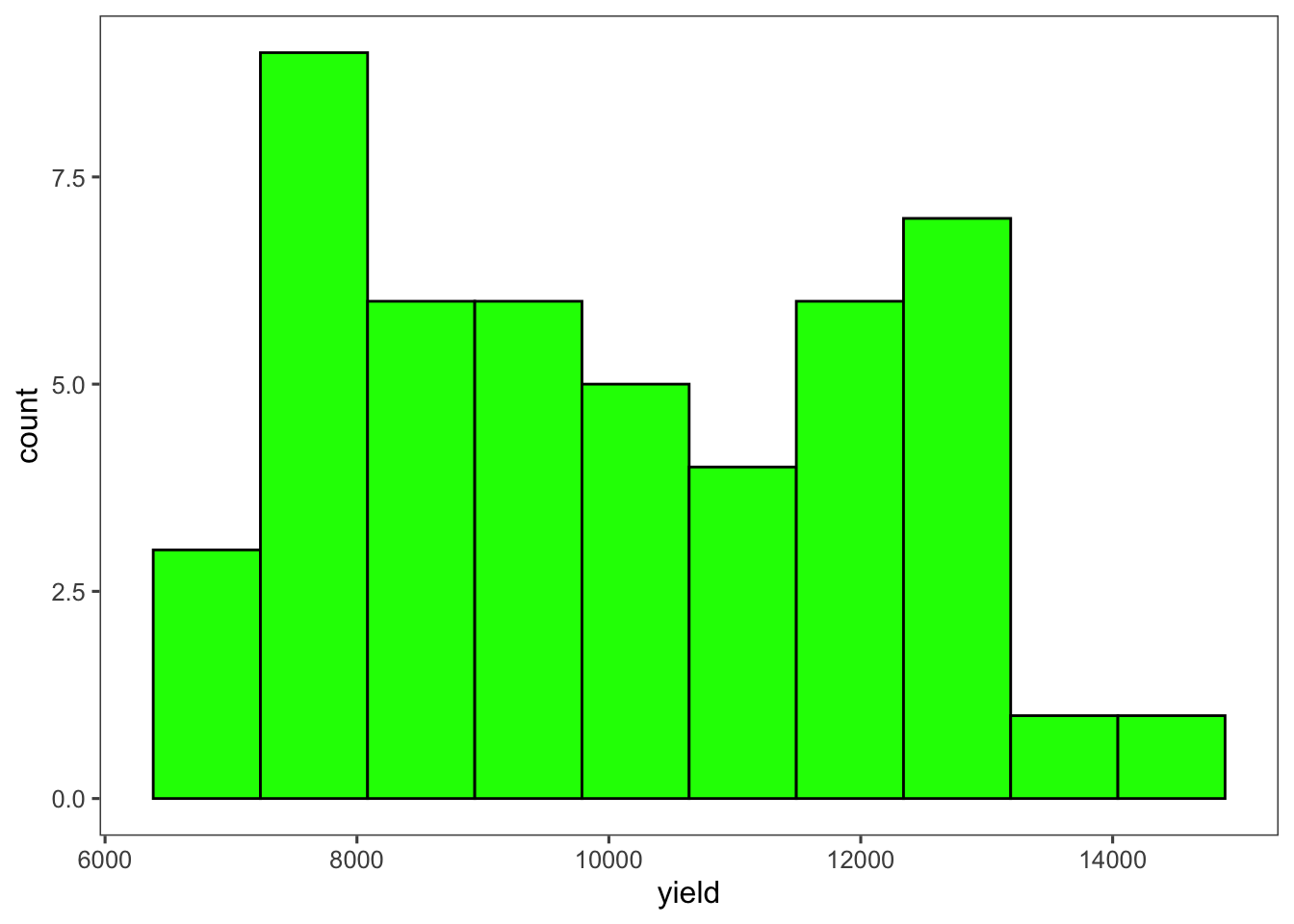
indexSe crea un histograma similar para la variable index, cambiando los colores de las barras.
p_index <- milho |>
ggplot(aes(x = index)) +
geom_histogram(bins = 10, color = "black", fill = "blue")+
theme_few()+
scale_color_few()
p_index 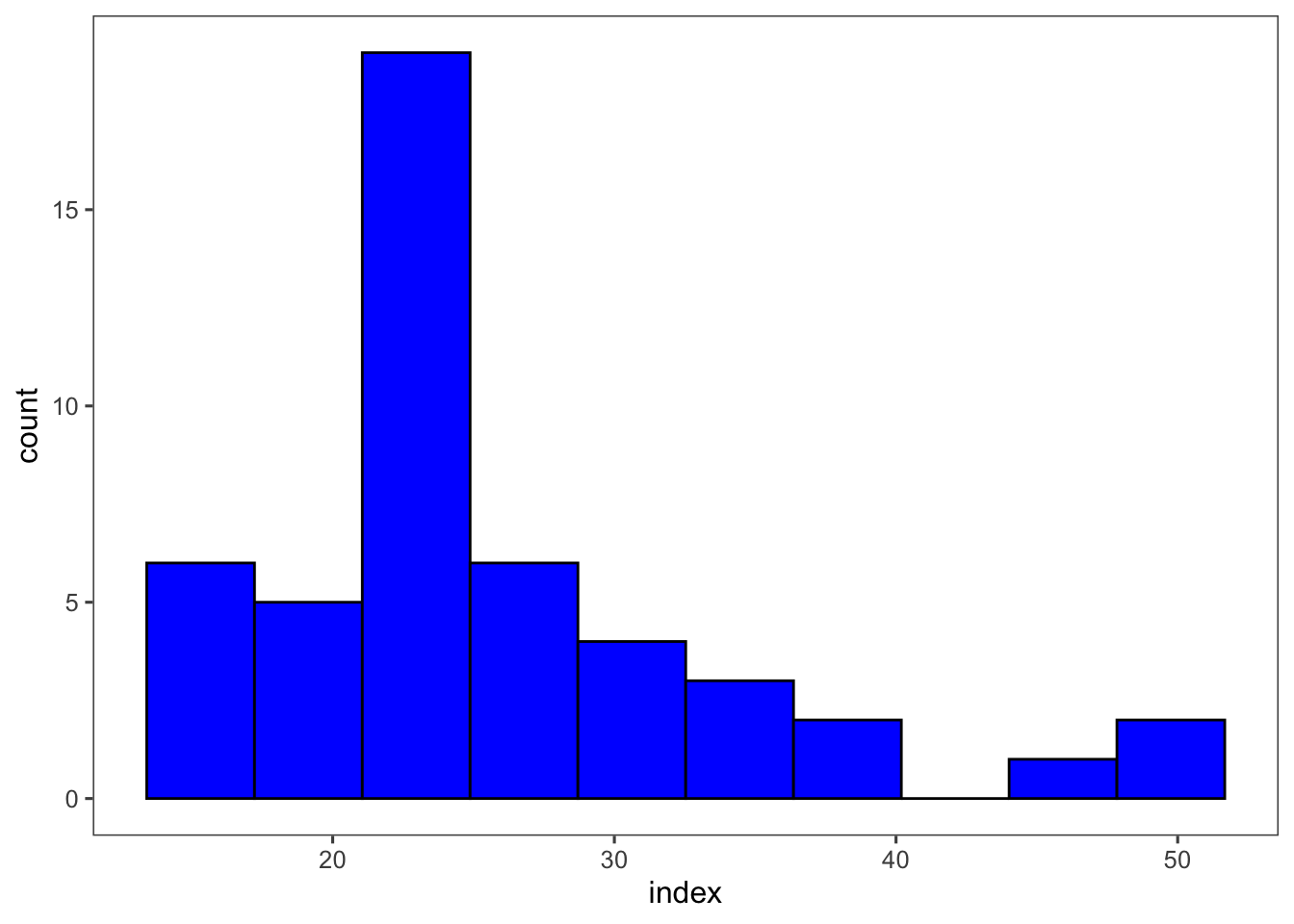
patchworkSe combinan los histogramas de yield y index utilizando patchwork, organizándolos en una única visualización.
library(patchwork)
(p_yield + p_index) +
plot_annotation(tag_levels = "A")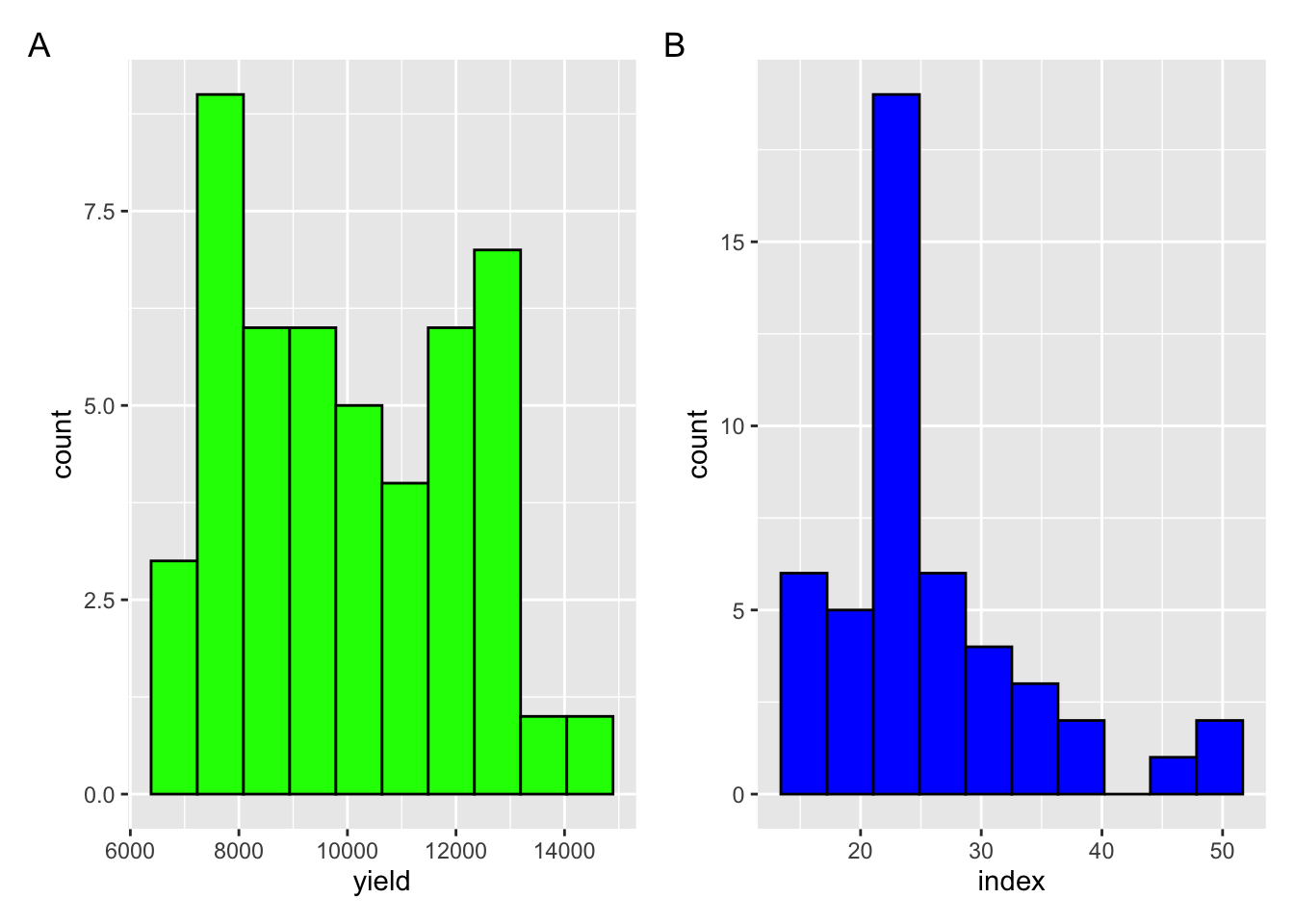
ggsave("figs/histograms.png", bg = "white")Los gráficos de densidad muestran la distribución de probabilidad de una variable continua. Se utilizan geom_density().
indexEn este ejemplo, se crea un gráfico de densidad para la variable index.
milho |>
ggplot(aes(x = index)) +
geom_density()+
theme_few()+
scale_color_few()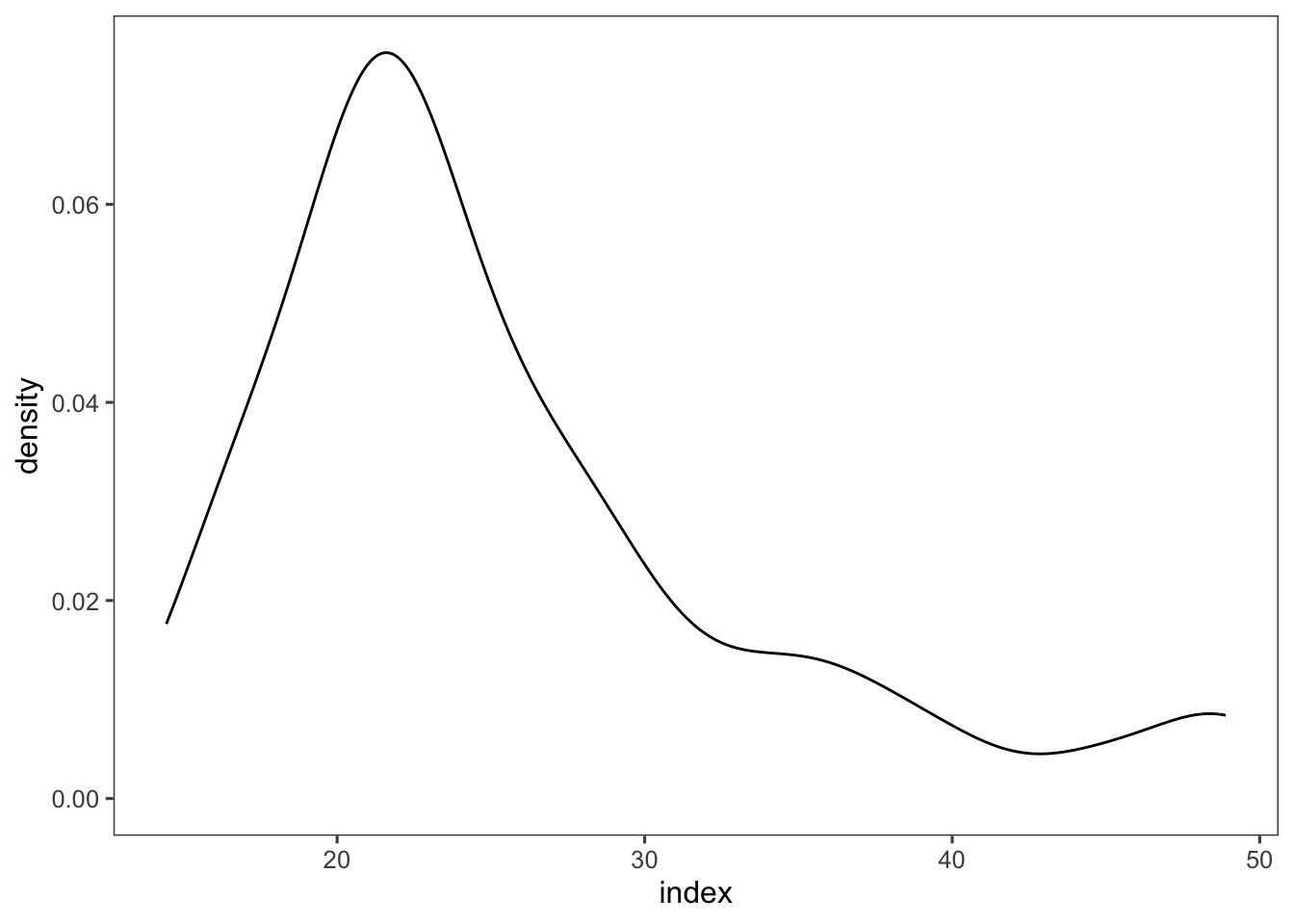
Se utiliza un nuevo subconjunto de datos (insect) para crear un gráfico de columnas (geom_col()), donde inseticida está en el eje x y value en el eje y. Se convierte el formato de ancho a largo con pivot_longer().
insect <- read_excel("dados-diversos.xlsx", "mortalidade")
insect |>
pivot_longer(2:3, names_to = "status", values_to = "value") |>
ggplot(aes(inseticida, value, fill = status)) +
geom_col()+
theme_few()+
scale_fill_manual(values = c("#669933", "#FFCC66")) 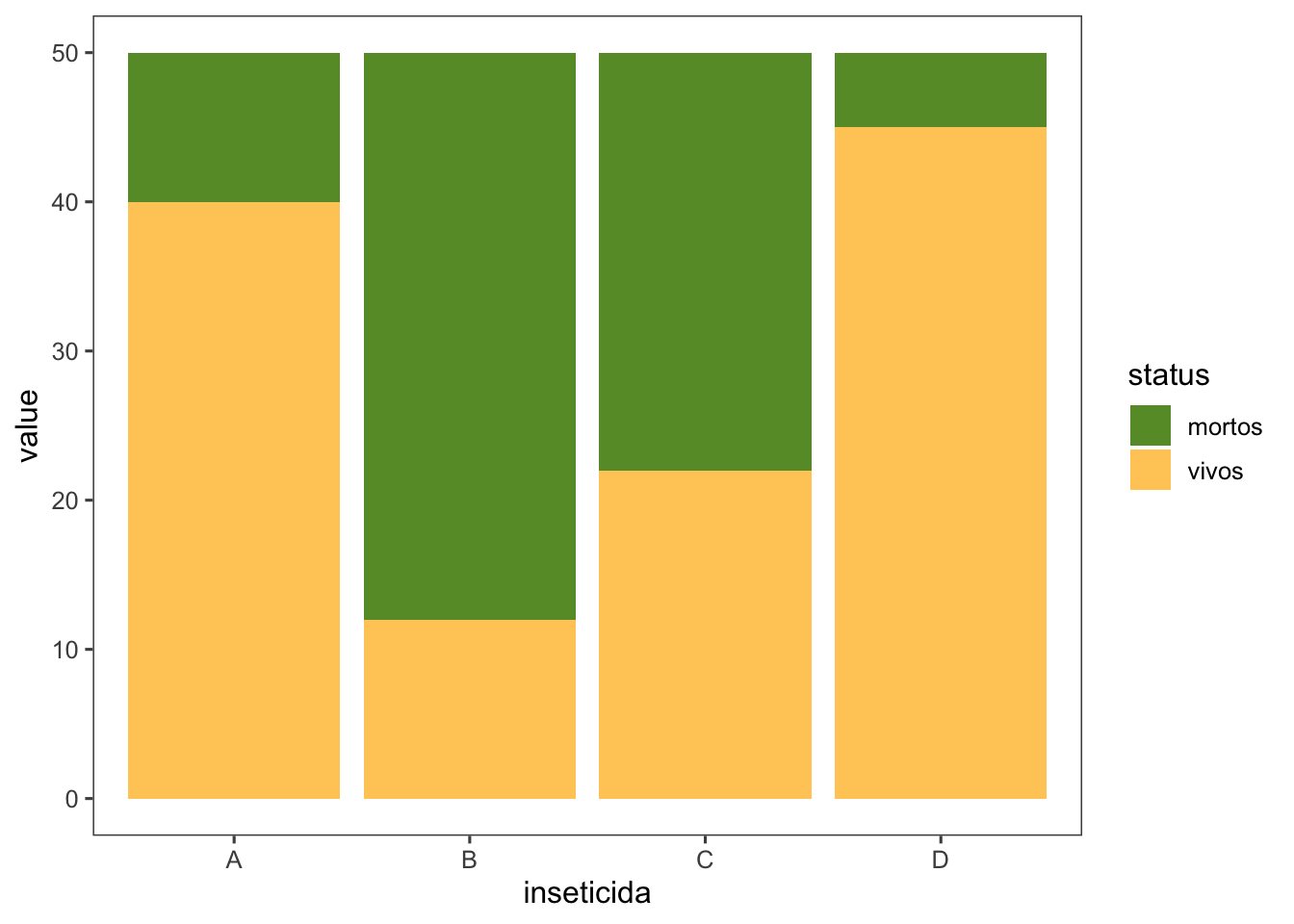
Este script en R demuestra cómo importar datos desde Excel, realizar visualizaciones como scatterplots, histogramas, gráficos de densidad y gráficos de columnas utilizando el paquete ggplot2 y otras herramientas como patchwork y tidyverse. Cada sección utiliza diferentes funciones y estéticas para explorar y visualizar datos de manera efectiva y clara.